from statistics import mean, stdev
def cv(x):
moy = mean(x)
s = stdev(x)
result = s / moy
return result
print(cv([5, 6, 3, 8, 9, 12]))0.4449099179002090616 mai 2023
![]()





Sourcehttps://xkcd.com/353/
![]()
Langage créé à la toute fin des années 80 - première version publique sortie en 1991.
Libre (régit par la Python Software Foundation License, équivalent à BSD)
Langage polyvalent, interprété, multi-paradigme (impératif, fonctionnel, OO, ..)
Typage dynamique fort (et duck typing)
Toujours en développement actif (dernière version en avril 2023)
![]()
Le projet R naît en 1993 comme un projet de recherche à l’université d’Auckland.
C’est une implémentation du langage S (développé au milieu des années 70 dans les laboratoires Bell)
Libre (licence GNU GPL)
Langage interprété, multi-paradigme (impératif, fonctionnel, OO, ..)
Typage dynamique
Toujours en développement actif (dernière version en avril 2023)
Centré autour de l’interpréteur R
Un IDE avec une position quasi-hégémonique : RStudio - Plus récemment, également des utilisateurs de Visual Studio Code
Une implémentation de référence du langage Python : CPython (mais d’autres implémentations : Jython, IronPython, PyPy, etc.)
Plusieurs distributions de Python (principalement Anaconda, une distribution des langages de programmation Python et R dédiée à la science des données et à l’apprentissage automatique)
Source: anaconda.org


![]()
PyPI (Python Package Index) / pypi.org : le dépôt tiers officiel du langage Python, qui héberge les packages sous la forme de fichiers sources et/ou de binaires précompilés (wheel) - publication facile du moment que ce qui est versé est dans les formats attendus (mais risque de typosquatting, etc.)
453 395 packages disponibles, soit 4 451 674 versions (au 11/05/2023)

Source : https://www.tidyverse.org/
Un point fort de Python est sa documentation officielle, qui contient tout le nécessaire pour utiliser le langage de manière proactive (tutoriel, référence de l’ensemble des fonctions / objets de tous les modules de la bibliothèque standard, etc.) et qui est mise à disposition dans plusieurs langues (Anglais, Français, Espagnol, Coréen, Japonais, Chinois, etc.).
Il n’existe toutefois pas un seul standard pour consulter la documentation des différents modules additionnels Python (cf. Documentation Matplotlib, Documentation pandas).



La documentation de R, tout aussi complète qu’elle soit est (selon moi) moins user-friendly et n’est disponible qu’en anglais.
En revanche, à l’inverse de Python, la documentation de tous les packages additionnels publiés sur le CRAN est consultable dans un même formalisme (en PDF depuis le site du CRAN , ou via des sites Web comme www.rdocumentation.org).


Les types natifs list (conteneur hétérogène) et array
(tableau typé) ne supportent les opérations vectorisées comme R.
NumPy (numpy.org).![]()
![]()
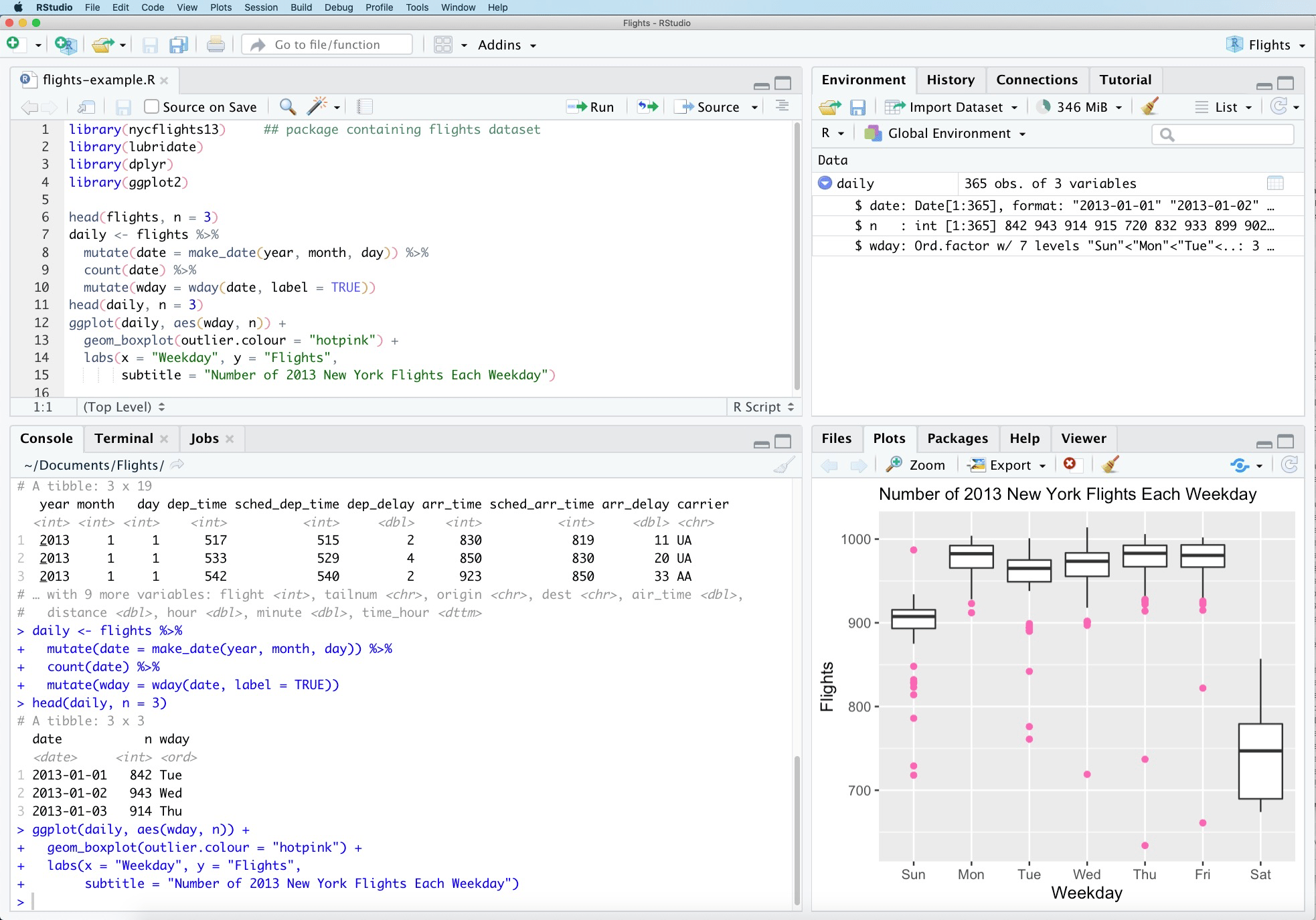
On utilisera généralement la bibliothèque Pandas (a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language)
Tout le nécessaire pour importer des données (CSV, HDF5, XML, Excel, BD relationnelle, etc.), les manipuler (group by, sélection, filtrage, etc.), les combiner (merge, join, concatenate, compare), etc.
Permet de travailler avec des séries temporelles
![]()


Statsmodels (Anova, régression linéaire, régression logistique, etc.)
Scikit-learn, développée par des membres de l’INRIA

Scikit-learn (Classification, Regression, Clustering, Dimensionality reduction, Model selection, Preprocessing)
TensorFlow (“Créez des modèles de machine learning pour la production avec TensorFlow”, développé par Google)
Keras (“Deep learning for humans” - pour interagir avec des algorithmes de réseaux de neurones profonds et d’apprentissage automatique, dont ceux de TensorFlow)
PyTorch (An open source machine learning framework that accelerates the path from research prototyping to production deployment)
![]()
mlr3 (“Efficient, object-oriented programming on the building blocks of machine learning”)
nnet (fournis avec R base)
TensorFlow for R (mais nécessite une installation Python avec TensorFlow)
Keras, Torch
En savoir plus sur le site du CRAN : https://cran.r-project.org/web/views/MachineLearning.html
![]()
Utilisation de matplotlib (et éventuellement de bibliothèques comme seaborn, basé sur matplotlib, qui offrent une API de plus haut-niveau pour faire facilement certains types de graphiques), principalement pour des graphiques statiques (images).
Bokeh principalement pour des graphiques interactifs.

data.frame de R base ou le type tibbleDataFrame de pandas en GeoDataFrame
Pour récupérer des données sous forme de triplets RDF… mais également pour modélisation ontologique
Différentes initiatives en R (rdflib, ontologyPlot, etc.), moins abouties à mon gout
Le langage Java reste probablement le langage de choix (Jena, OWLAPI, RDF4J, différents moteurs d’inférence, etc.)
![]()
Quarto : “An open-source scientific and technical publishing system” (R, Python, Julia, Observable JavaScript)
Principe de la programmation lettrée (litterate programming)
Pour préparer différents types de documents (page HTML, slides, PDF, document Word, etc.)



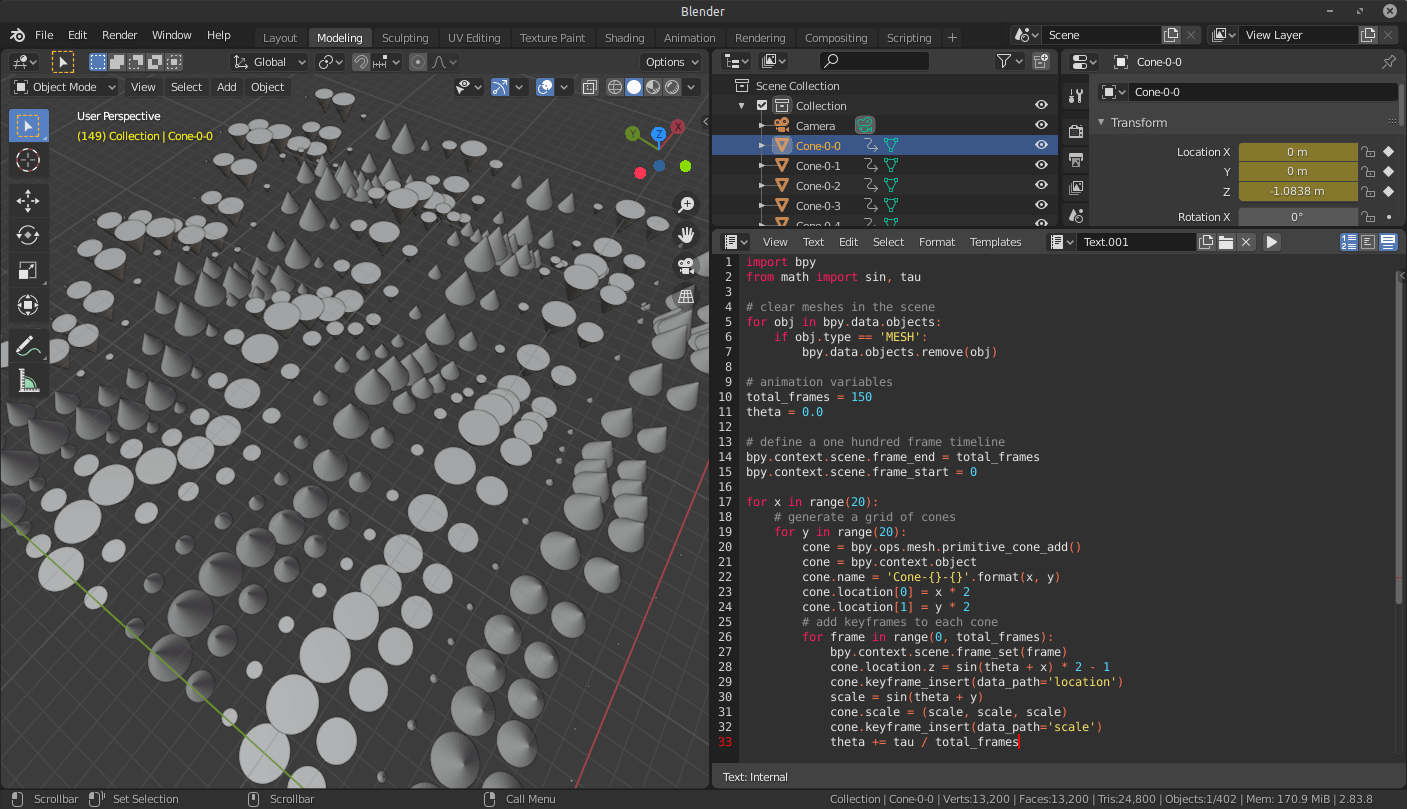
Blender : un logiciel libre de modélisation, d’animation par ordinateur et de rendu en 3D
Intègre une console Python, permet d’interagir avec de nombreux aspects de Blender dont notamment l’animation, le rendu, l’import et l’export, la création d’objet et l’éxécution automatisée de tâches répétitives
Pour en savoir plus: https://docs.blender.org/api/current/info_overview.html