Exercice noté, à faire à la maison : Boite à outils de géotraitement¶
Objectif¶
Découvrir et utiliser les algorithmes de la boite à outils de géotraitement (processing algorithms) en Python.
Combiner plusieurs géotraitements pour répondre à une question d’analyse spatiale.
Nouvelles notions¶
L’ensemble des géotraitements disponibles sous forme de boites de dialogues dans QGIS est également accessible au travers de l’API Python. C’est également le cas pour les géotraitements proposées dans QGIS par les extensions GRASS, SAGA et GDAL.
Contraitement aux manipulations que nous avons effectuées auparavant, ces géotraitements prennent en entrée une (ou plusieurs) couche(s) et produisent généralement une couche en sortie. Il s’agit par exemple de traitements tels que :
Création de Polygones Voronoi
Création d’une grille au format vecteur
Fusion des entités d’un couche
Rastériserisation d’une couche vecteur
Etc.
En utilisant le code suivant, il est possible de lister l’ensemble des algorithmes disponibles dans QGIS :
for alg in QgsApplication.processingRegistry().algorithms():
print("{} --> {}".format(alg.id(), alg.displayName()))
Le texte qui s’affiche est de la forme :
...
native:centroids --> Centroïdes
native:clip --> Couper
...
La partie de gauche désigne l’idenfifiant de l’algorithme (native:centroids par exemple)
et celle de droite son intitulé (Centroïdes par exemple) dans la langue utilisée par QGIS (ici le français - certains intitulés ne sont toutefois pas traduits).
Il est ainsi possible d’accéder en Python à l’ensemble des géotraitements de la boite à outils.
L’accès à ces algorithmes se fait via le module processing.
import processing
➜ La fonction algorithmHelp va permettre d’afficher l’aide d’un algorithme:
processing.algorithmHelp("native:centroids")
Il est indispensable de lire la documentation d’un algorithme avant de l’utiliser : c’est elle qui indique quels sont les paramètres requis pour l’utiliser.
L’aide des différents géotraitements peut également être affichée au format HTML à partir de la page : https://docs.qgis.org/3.10/en/docs/user_manual/processing_algs/index.html.
Centroïdes (native:centroids)
Cet algorithme créé un nouvelle couche de type point, ou les points représentent le barycentre des entités d'une couche d'entrée.
Les attributs associés aux points dans la couche de sortie sont ceux des points de la couche d'origine.
----------------
Input parameters
----------------
INPUT: Couche source
Parameter type: QgsProcessingParameterFeatureSource
Accepted data types:
- str: ID de couche
- str: nom de couche
- str: couche source
- QgsProcessingFeatureSourceDefinition
- QgsProperty
- QgsVectorLayer
ALL_PARTS: Créer un centroïde pour chaque partie
Parameter type: QgsProcessingParameterBoolean
Accepted data types:
- bool
- int
- str
- QgsProperty
OUTPUT: Centroïdes
Parameter type: QgsProcessingParameterFeatureSink
Accepted data types:
- str: fichier vecteur de destination, par ex. 'd:/test.shp'
- str: 'memory:' pour stocker le résultat dans une couche temporaire en mémoire
- str: using vector provider ID prefix and destination URI, e.g. 'postgres:…' to store result in PostGIS table
- QgsProcessingOutputLayerDefinition
- QgsProperty
----------------
Outputs
----------------
OUTPUT: <QgsProcessingOutputVectorLayer>
Centroïdes
Cette aide nous apprend :
Que l’algorithme s’utilise avec 3 paramètres d’entrée :
INPUT,ALL_PARTSetOUTPUT(nous allons voir comment les utiliser simplement ensuite),Que le résultat attendu est de type
QgsProcessingOutputVectorLayer: cet objet va nous permettre d’obtenir une couche de typeQgsVectorLayercomme manipulée dans les TP précédents si l’éxécution se déroule sans problème.
➜ La fonction run va permettre d’éxécuter l’algorithme.
Son premier argument est l’identifiant de l’algorithme à éxécuter et son second argument est un dictionnaire Python (objet dict) décrivant
les paramètres de l’algorithme (couche(s) en entrées, type de sortie, éventuelles options.)
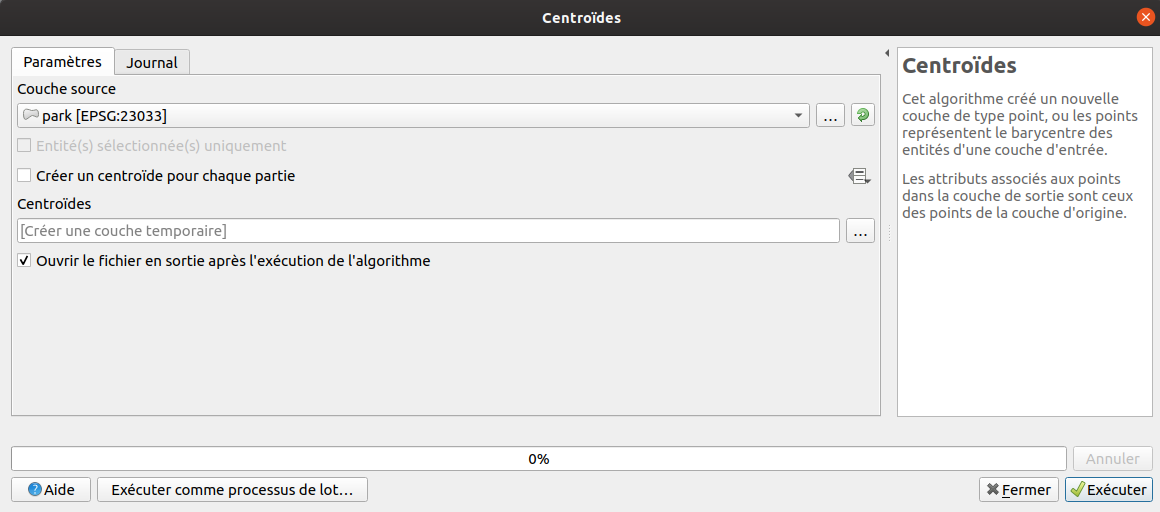
L’exemple suivant utilise une de mes couches (nommée park dans mon projet QGIS) pour calculer le centroide de chaque entité.
Le résultat est stocké dans une couche temporaire en mémoire et est ajouté au projet actuel.
layer = QgsProject.instance().mapLayersByName("park")[0]
result = processing.run(
"native:centroids",
{'INPUT': layer, 'ALL_PARTS': False, 'OUTPUT': 'memory:'}
)
QgsProject.instance().addMapLayer(result['OUTPUT'])
L’exécution du code précédent correspond ainsi à l’action suivante dans l’interface de QGIS :
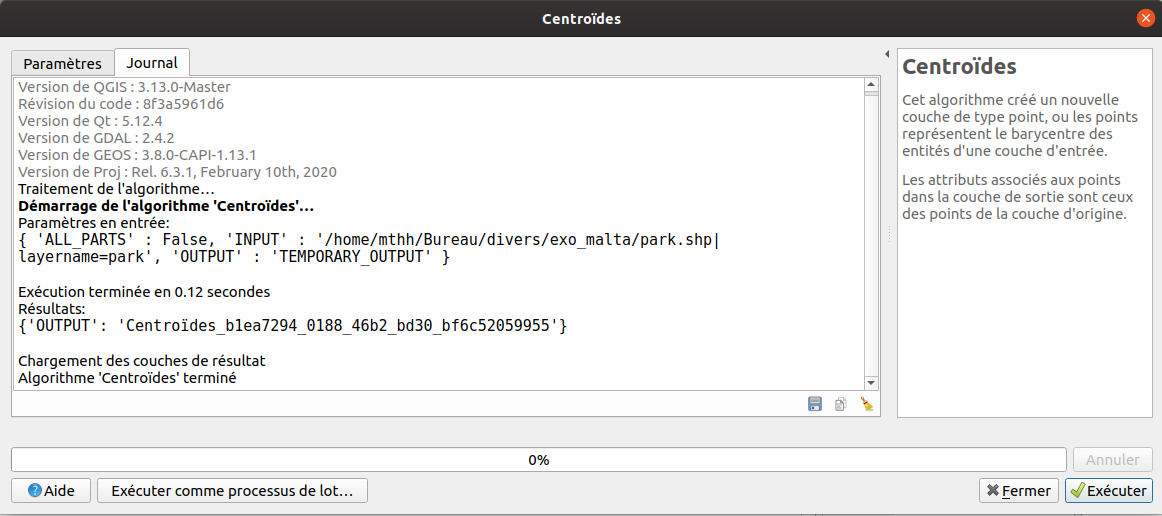
Dans l’interface, on retrouve également après l’éxécution, dans l’onglet Journal le dictionnaire des paramètres en entrée
utilisé pour ce géotraitement :
Puisque l’on obtient une nouvelle couche, il est ainsi possible d’enchainer plusieurs traitements de ce type de manière simple. Si je cherche à créer des polygones de Voronoi qui correspondent à mes parks (cet algorithme nécessite une couche de points en entrée), je peux ainsi réaliser les traitements suivants :
input_layer = QgsProject.instance().mapLayersByName("park")[0]
# 1. Calcul des centroides
result_centroids = processing.run(
"native:centroids",
{'INPUT': input_layer, 'ALL_PARTS': False, 'OUTPUT': 'memory:'})
centroid_layer = result_centroids['OUTPUT']
# 2. Calcul des polygones de voronoi
# et choix d'un chemin pour enregister le résultat :
result_voronoi = processing.run(
"qgis:voronoipolygons",
{'INPUT': centroid_layer, 'BUFFER': 5, 'OUTPUT': 'memory:'})
# 3. Ajout des polygones de voronoi au projet
QgsProject.instance().addMapLayer(result_voronoi['OUTPUT'])
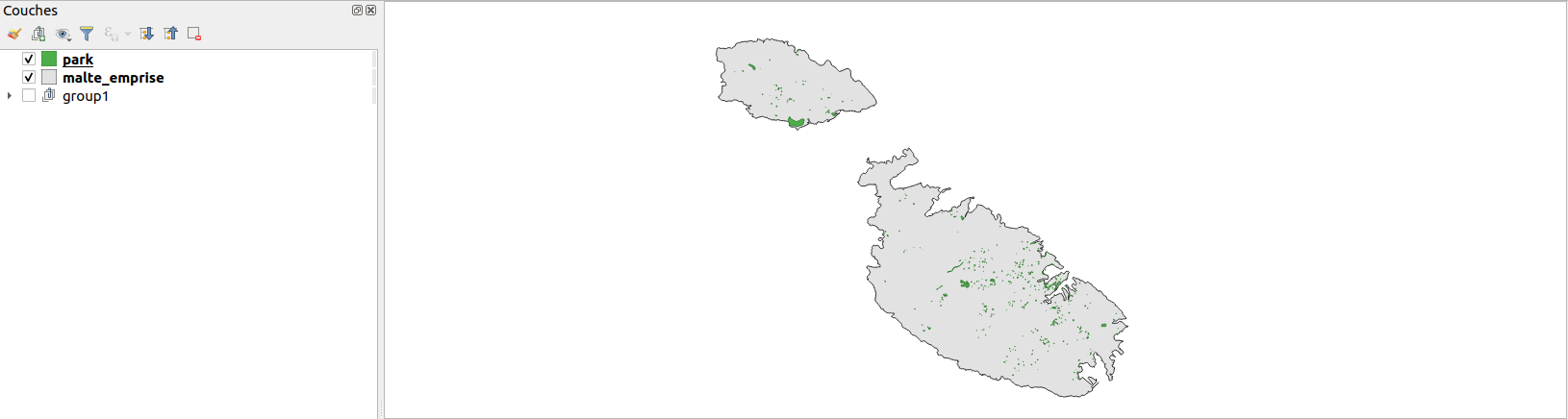

Ici result_voronoi['OUTPUT'] est un objet de type QgsVectorLayer comme manipulé dans les TP précédents : il est possible de changer son nom dans l’interface et ceci
est conseillé afin d’identifier plus facilement vos couches.
result_voronoi['OUTPUT'].setName('voronoi_park')

Exercice¶
Nous souhaitons en savoir plus sur le profil socio-démographique des habitants de Paris en utilisant un découpage original : celui qui peut être obtenus à partir des stations de métros.
En effet nous pourrions vouloir répondre à plusieurs questions telles que:
quels sont les niveaux de revenus à proximité de ma station de métro ?
quelles stations de métro sont situées dans les zones les plus densément peuplées ?
aux alentour de quelles stations sont principalement localisées les résidences secondaires ?
Nous allons répondre à la première de ces questions en utilisant les couches de données suivantes :
IRIS_MENAGE_PARIS: les données socio-économique disponibles au niveau des IRIS situés à Paris (les données proviennent de l’APUR [1] et ont été enrichies avec des données de l’INSEE [2]). Le principal champ qui nous intéresse dans cette couche estRDEC_MED16: le revenu médian déclaré par ménage.STATION_METRO_PARIS: les stations de métro situées dans Paris (les données proviennent de l’APUR [3]). Cette couche dispose notamment d’un champ nomméL_STATION: le nom de la station.
0. Télécharger l’archive zippée qui contient les données : https://mthh.github.io/TP_PythonQGIS/_static/data_pyqgis.zip
La décompresser dans votre espace de travail.
Créer un nouveau projet QGIS utilisant la projection EPSG:2154 (Lambert 93 / RGF 93).
Ajouter les couches STATION_METRO_PARIS.shp et IRIS_MENAGE_PARIS.shp et s’assurer qu’elles sont bien dans la même projection que le projet.
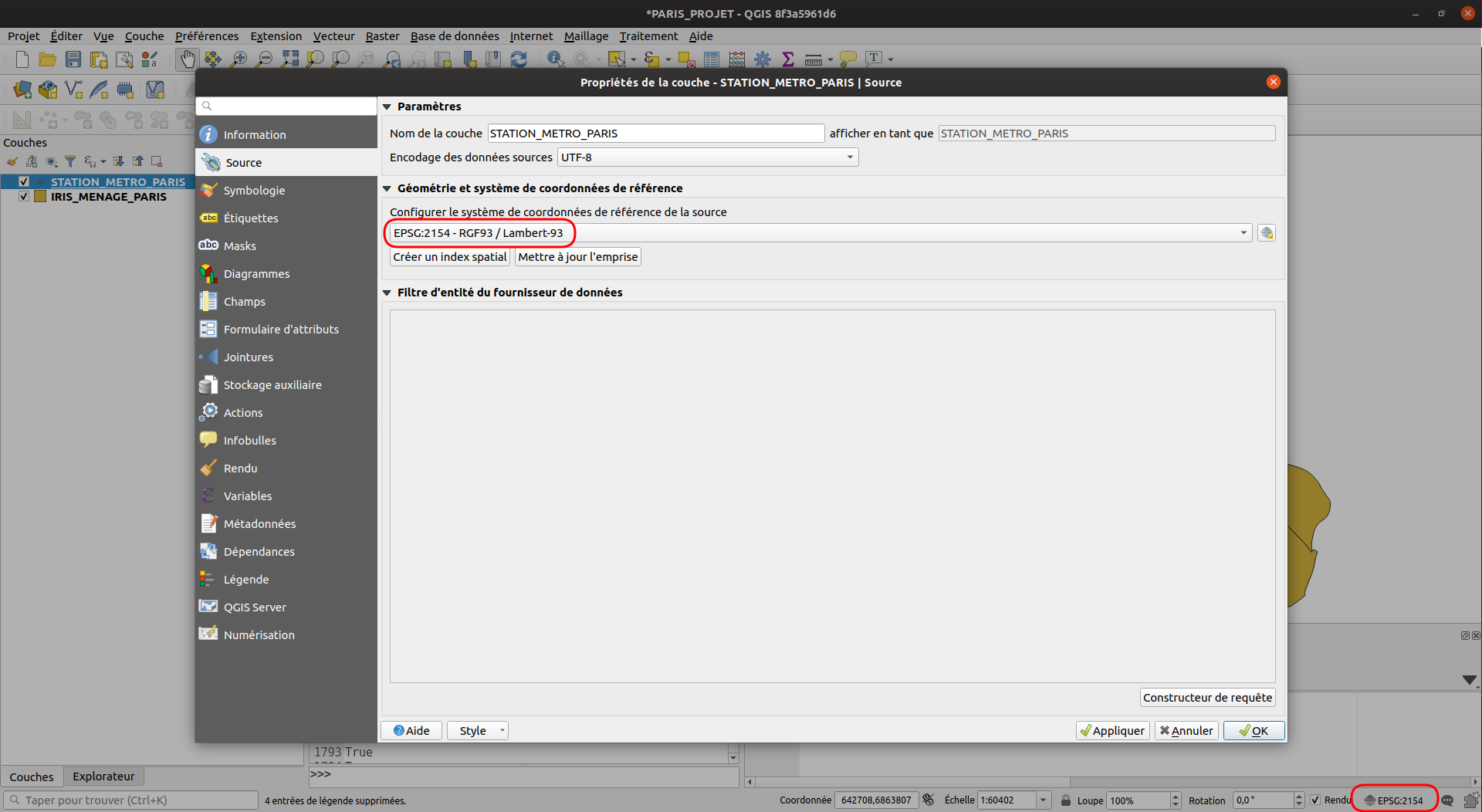
⚠ L’ensemble des étapes suivantes doit être effectué en Python. Une capture d’écran vous indique quel est le résultat attendu à l’issue de chaque étape. ⚠
1. Obtenir une référence Python aux couches STATION_METRO_PARIS et IRIS_MENAGE_PARIS. Appliquer le style du fichier Style_STATION_METRO_PARIS.qml à la couche STATION_METRO_PARIS.
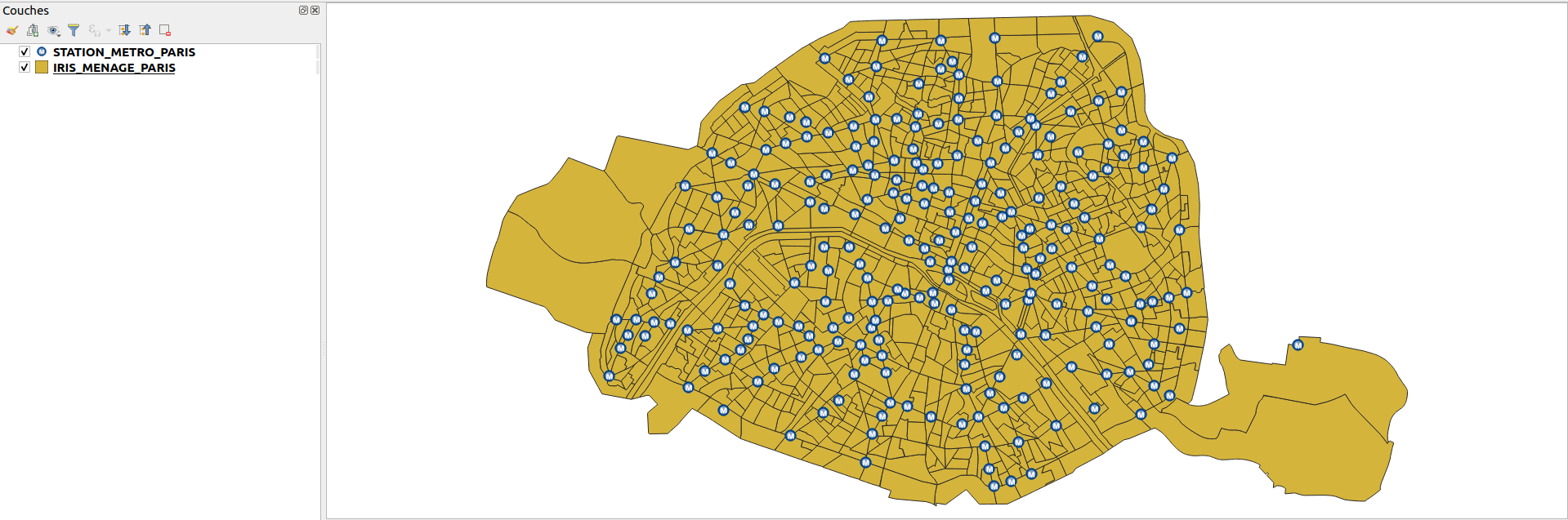
2. À partir de la couche IRIS_MENAGE_PARIS et en utilisant l’aglorithme native:dissolve, créer une couche correspondant à l’emprise de la ville de Paris.
L’ajouter au projet actuel et la renommer COMMUNE_PARIS.
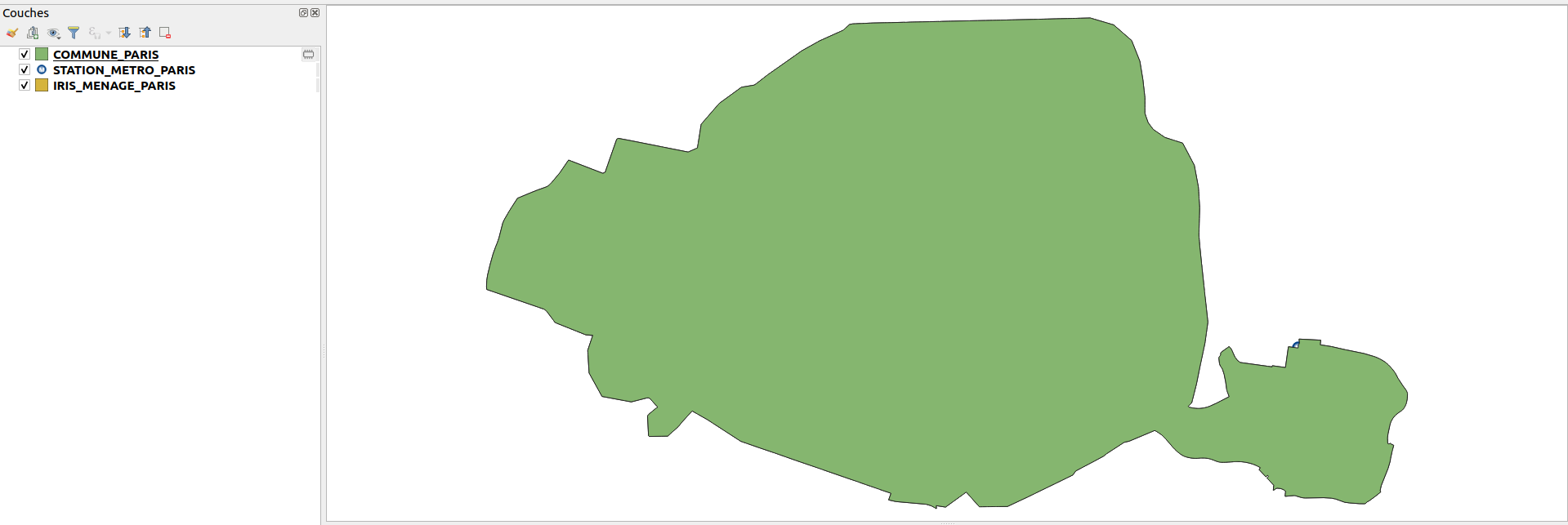
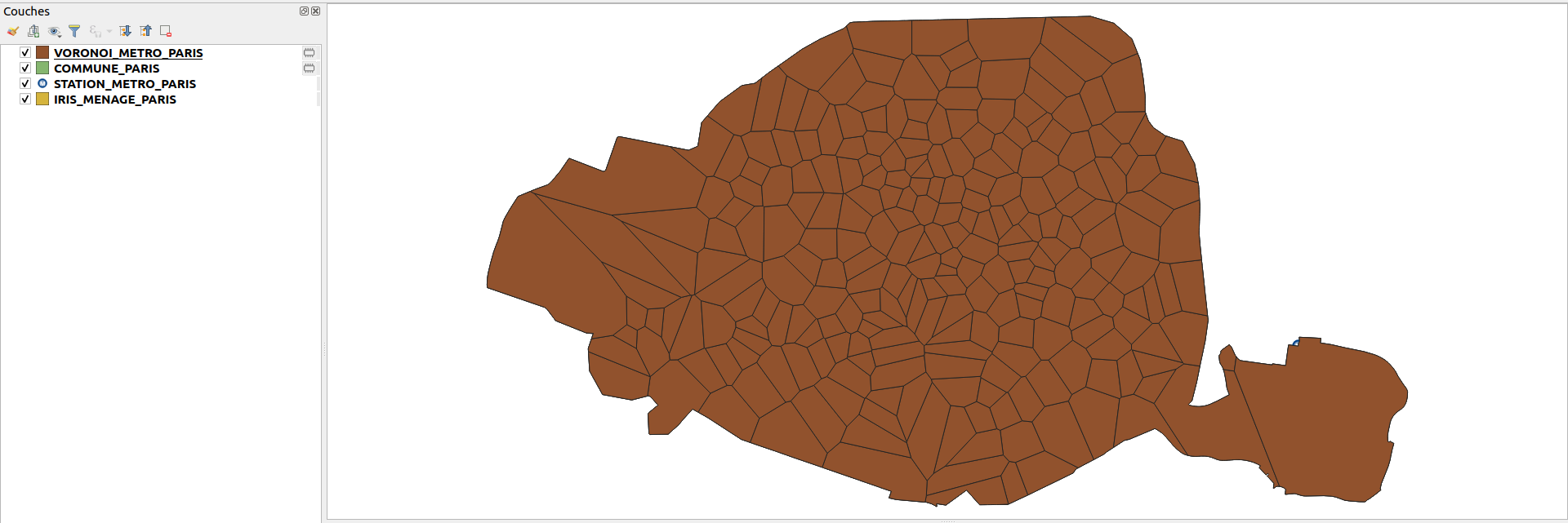
3. En vous aidant de l’exemple vu au dessus, calculer les polygones de voronoi qui correspondant à la couche STATION_METRO_PARIS en utilisant un buffer de 20%. Il n’est pas nécessaire d’ajouter ce résultat intermédiaire au projet.
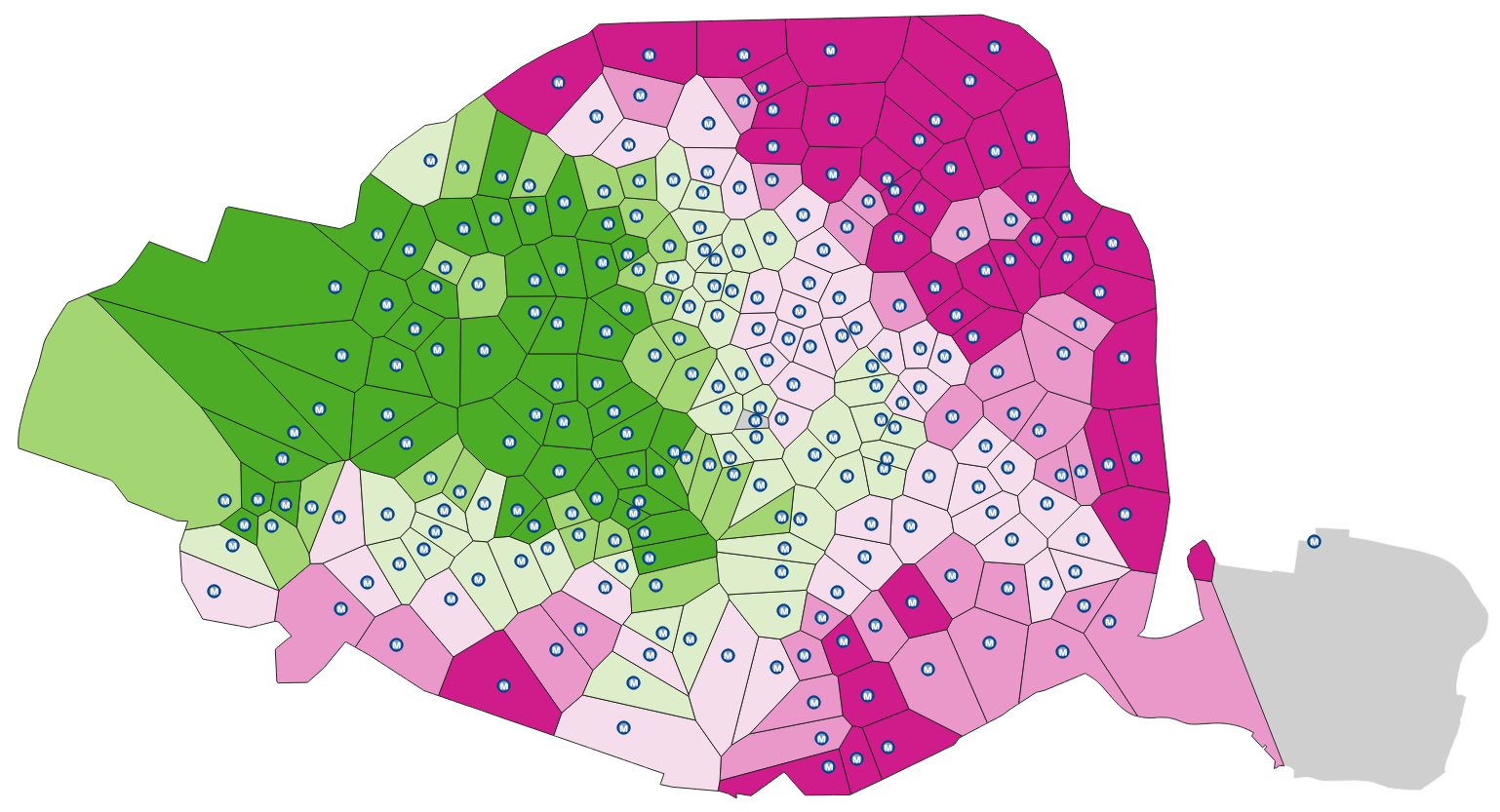
En utilisant vos connaissances en SIG, sélectionner puis éxécuter ensuite le géotraitement qui vous permet de découper ces polygones de voronoi par la couche obtenue COMMUNE_PARIS afin d’obtenir le résultat qui suit.
Ajouter ce résultat au projet actuel et renommer la couche : VORONOI_METRO_PARIS.
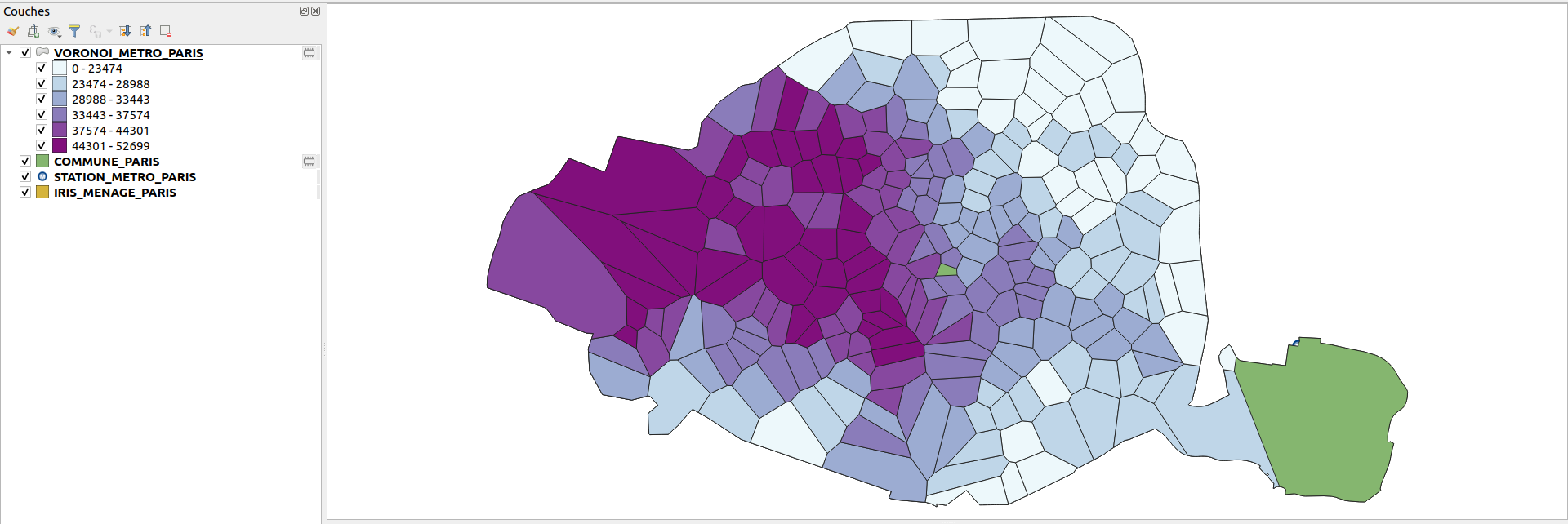
4. En utilisant les notions vues dans les TP précédents, calculer, pour chaque polygone de Voronoi, la moyenne des salaires médians (champ RDEC_MED16) des IRIS intersectés (couche IRIS_MENAGE_PARIS).
Pour chaque polygone de Voronoi, cette valeur doit être stockée dans le champ MOY_RDEC (pour moyenne des revenus déclarés) qu’il est nécessaire de créer au préalable.
⚠ Attention lors de la réalisation de ce calcul : les IRIS qui présentent la valeur 0 ne doivent pas être pris en compte dans le calcul de la moyenne (la valeur 0 n’indique pas un salaire médian de 0 mais la non restitution de la valeur de l’indicateur pour l’IRIS concerné pour des raisons de confidentialité des données).
Enfin, appliquer le style Style_VORONOI_METRO_PARIS.qml à la couche VORONOI_METRO_PARIS.
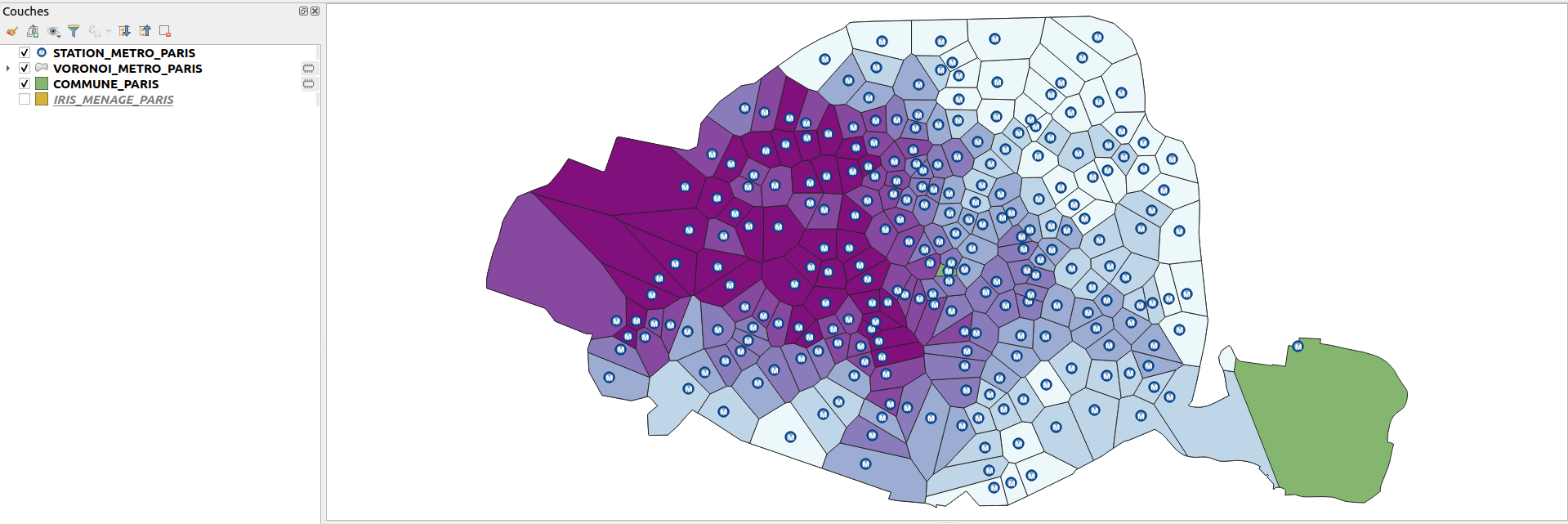
5. En utilisant des éléments vus dans les TP précédents, écrire le code nécessaire à organiser les couches afin qu’elles apparaissent dans l’ordre de la liste qui suit :
layer_order = ['STATION_METRO_PARIS', 'VORONOI_METRO_PARIS', 'COMMUNE_PARIS', 'IRIS_MENAGE_PARIS']
6. Écrire une fonction Python affiche_salaire_station qui accepte un argument, le nom d’une station de métro, et qui affiche la valeur calculée à l’étape 4.
Cette fonction doit donc se présenter de la forme suivante :
def affiche_salaire_station(nom_station):
# le code permettant d'afficher
# la valeur pour la station 'nom_station'
Par exemple si on l’invoque avec le nom PORTE DE PANTIN on doit obtenir le résultat suivant :
affiche_salaire_station('PORTE DE PANTIN')
# "La moyenne des salaires médians autour de la station 'PORTE DE PANTIN' est de 17048.71 euros"
Attention à prendre en compte le cas ou le nom donné en argument ne correspond pas à une station existante :
affiche_salaire_station('XYZ')
# "La station 'XYZ' n'existe pas"
🚀 Question bonus 🚀 Lors de l’étape 4 le calcul réalisé n’est pas très précis : en effet, tous les IRIS qui intersectent un polygone de Voronoi sont pris en compte à égalité alors qu’il serait plus correct de prendre en compte ces valeurs au prorata des surfaces concernées lors du calcul de la moyenne.
Répéter la logique de la question 4 en mettant en oeuvre la consigne précédente en stockant cette fois le résultat dans un champ appelé MOY_RDEC_P (pour moyenne des revenus déclarés au prorata).
Footnotes