dataset = [{name: 'Allemagne', value: 65},{name: 'Albanie', value :59}, {name: 'Italie', value: 80}, {name: 'France', value: 81}, { name: 'Gabon', value: 56}, {name: 'Maroc', value: 55},{name: 'Égypte', value: 40}]Règles et conseils pour la conception de visualisation de données
Cours 2 - 2025-2026
Matthieu Viry 
CNRS / UAR 2414 RIATE
September 9, 2025
Plan
- Perception visuelle
- Théorie de la Gestalt
- La sémiologie graphique de Jacques Bertin (et ses successeurs)
- Conseils pour la conception de visualisation de données

Source : Four color theorem, Carlos ZGZ, public domain licence.
Théorie de la Gestalt
- Une théorie de la perception qui s’intéresse à la manière dont les êtres humains perçoivent les objets.

Développée par des psychologues allemands au début du XXe siècle.
La théorie de la Gestalt est utilisée en design, en psychologie, en ergonomie, en informatique, etc. … et en visualisation de données.
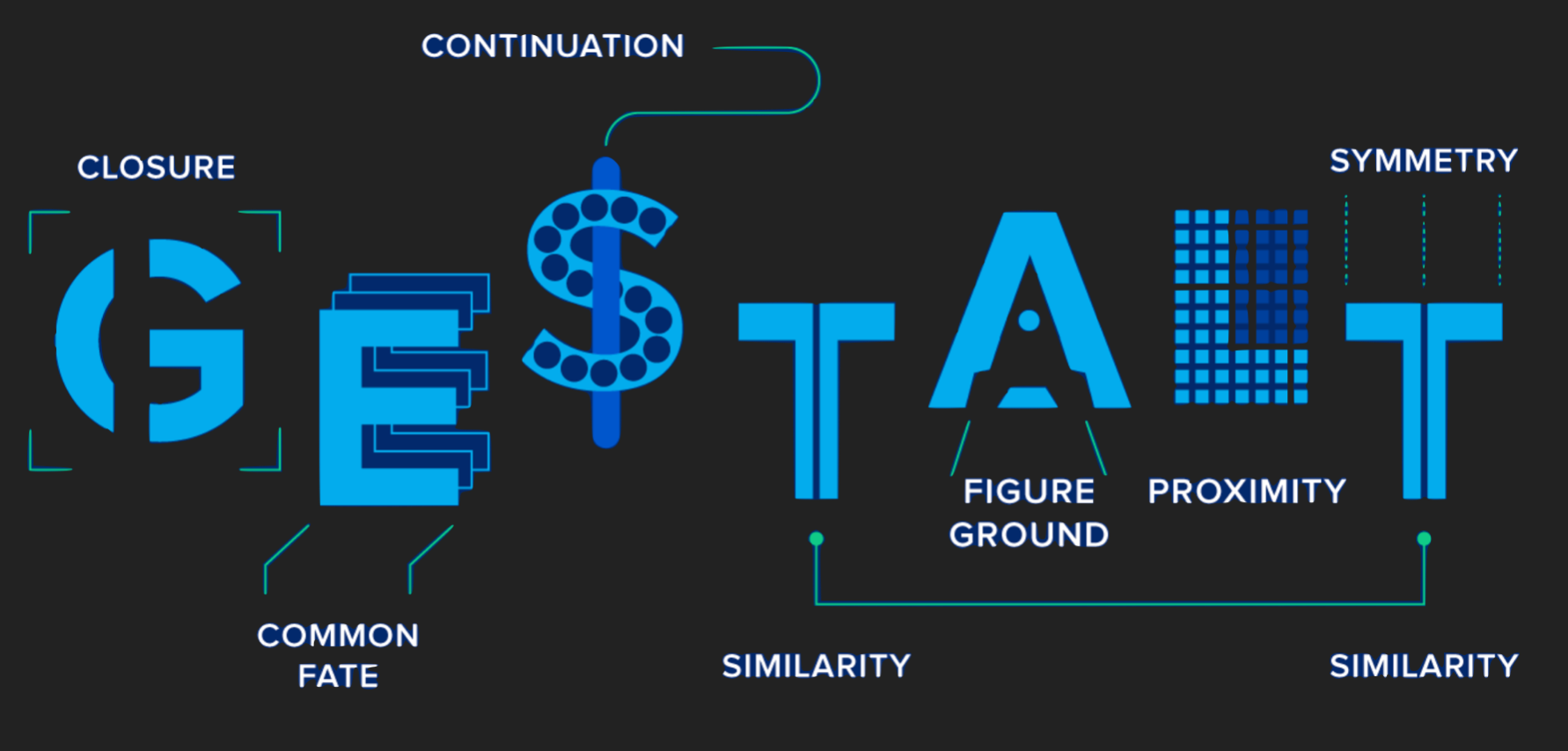
Les principales lois de la Gestalt
Pour résumer…
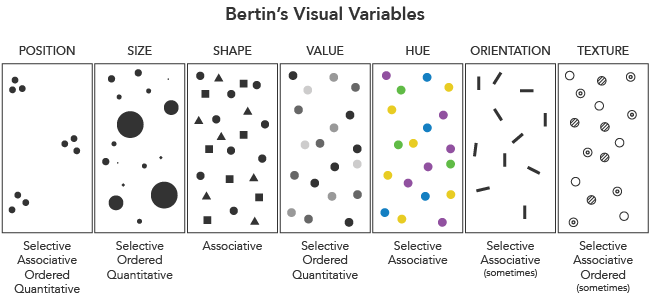
Les variables visuelles et leurs propriétés
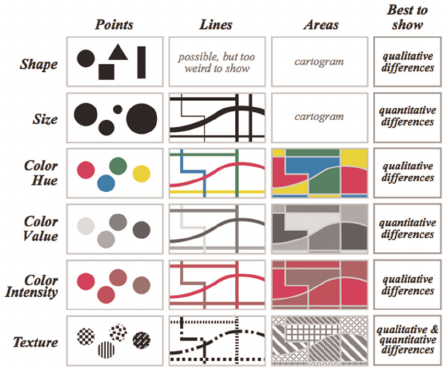
Les variables visuelles et leurs propriétés
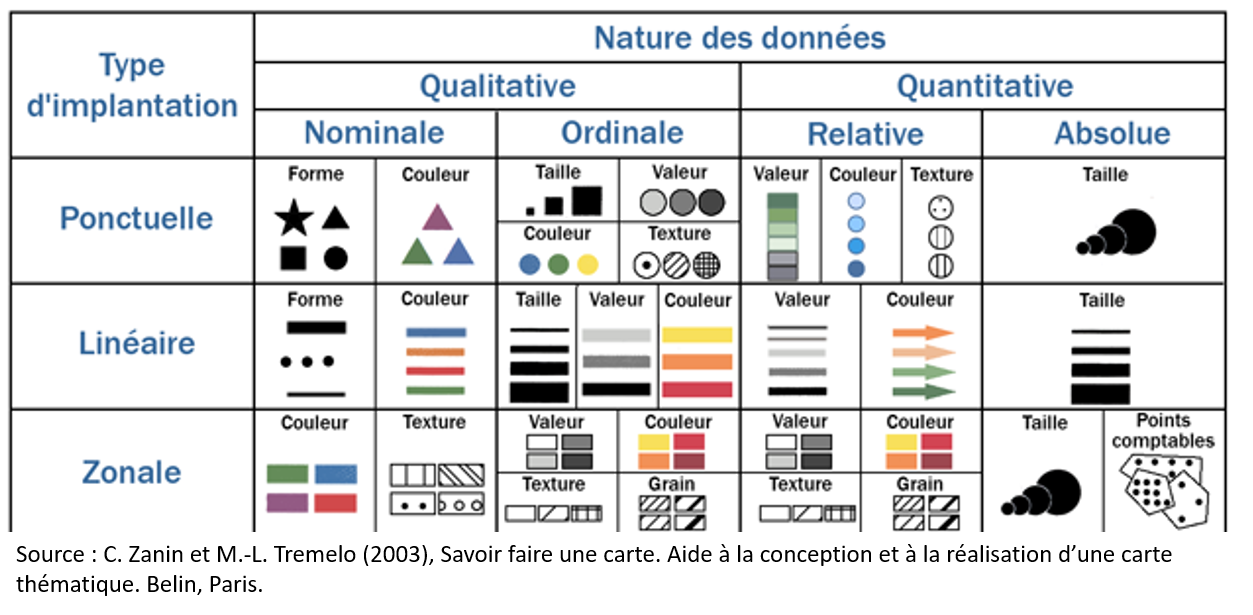
Les variables visuelles et leurs propriétés
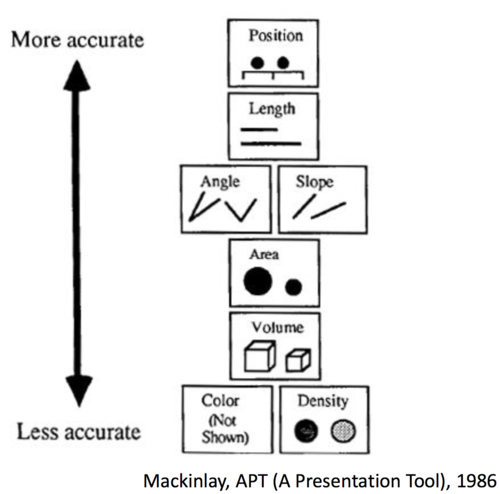
Les successeurs de Jacques Bertin : Cleveland & McGill, Mackinlay, etc.
- Depuis les travaux de Jacques Bertin, d’autres chercheurs ont proposé des typologies de variables visuelles et de leurs propriétés.
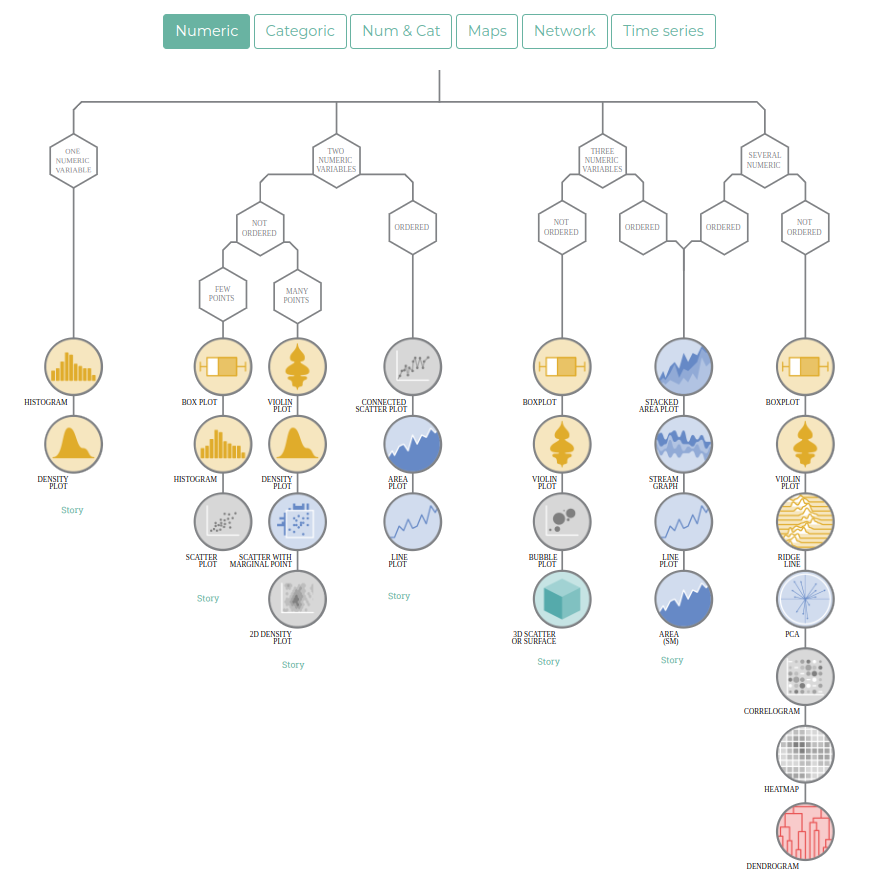
Choisir une forme de graphique adapté
Cf. le cours d’introduction et les exercices en TP
Différentes ressources peuvent aider à choisir le bon type de graphique :
Clareté et simplicité
Les visualisations de données doivent être simples à comprendre : de manière générale, il faudra essayer de choisir la manière la plus simple de transmettre l’information.
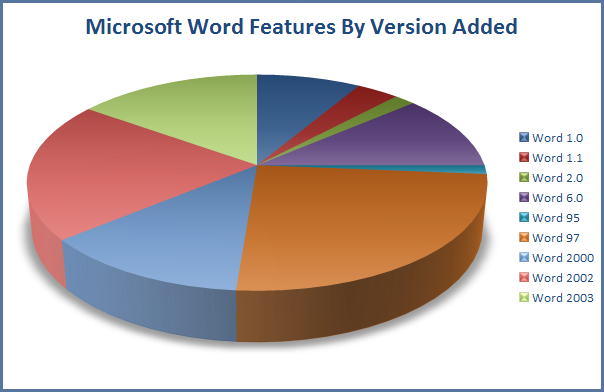
Éviter les éléments visuels complexes et inutiles qui pourraient distraire de l’objectif principal de la visualisation (3D, effets spéciaux, etc.).

Titre, description, source, légende, axes, etc.

Le principe de la proportionnalité et la coupure de l’axe Y
- The principle of proportional ink (Bergstrom and West, 2016)
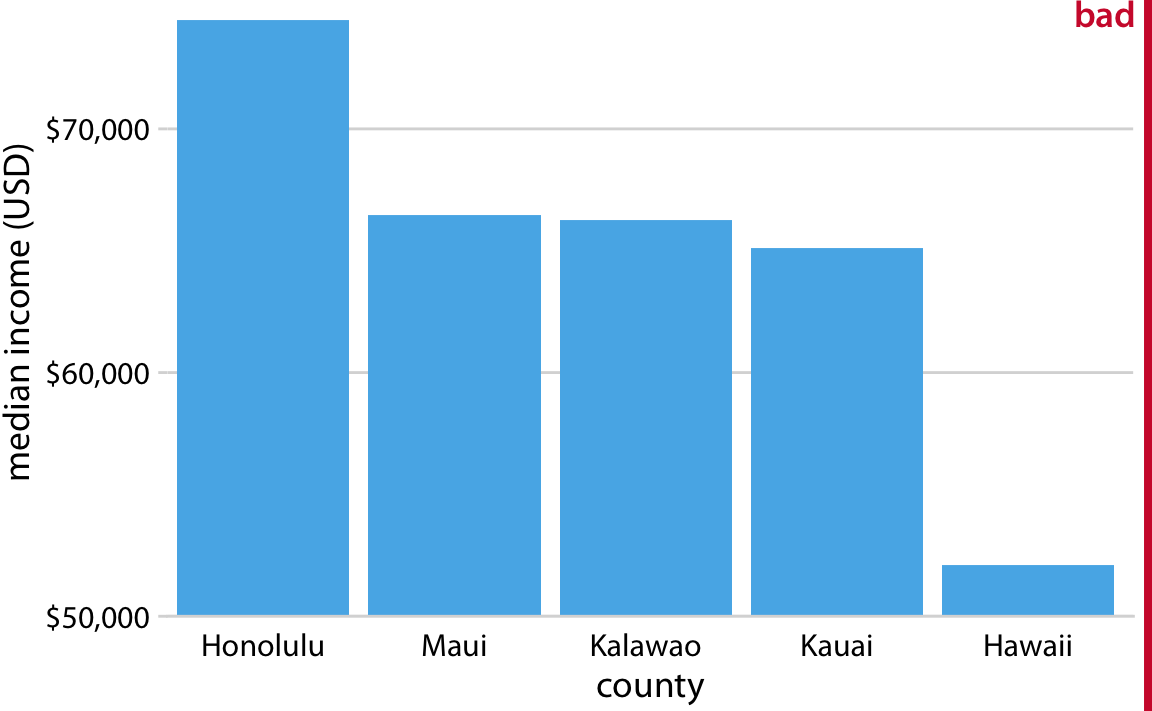
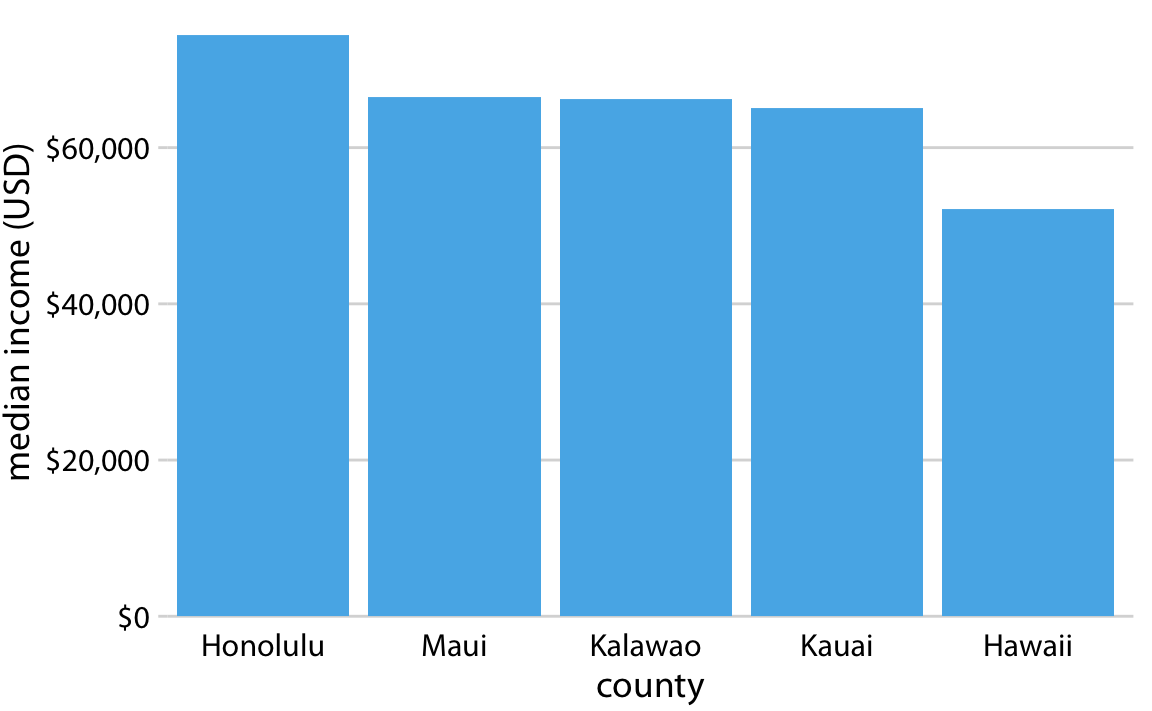
Le principe de la proportionnalité et la coupure de l’axe Y (ou X !)

Source : https://twitter.com/Motorsport/status/1432668101905195013/photo/1

Source : https://observablehq.com/@kenklin/shortest-f1-races-by-distance
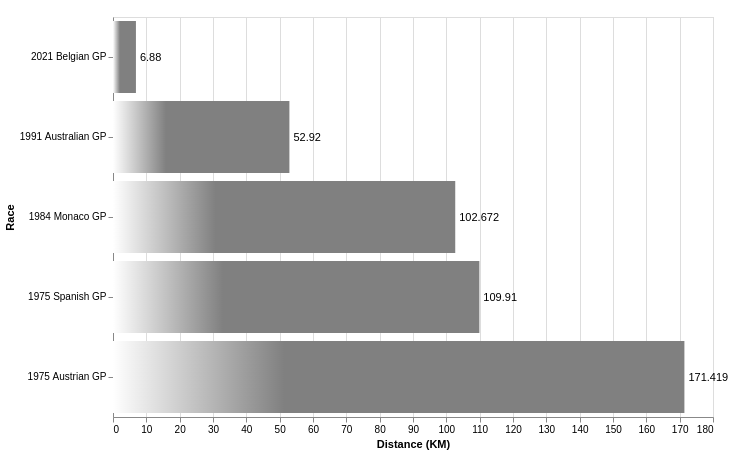
Le principe de la proportionnalité et la coupure de l’axe Y
- D’autres auteurs (Wilke, 2019) le déconseillent fortement, même pour des séries temporelles, et conseillent l’utilisation éventuelle d’autres représentation (différence par rapport à une valeur de référence, etc.)
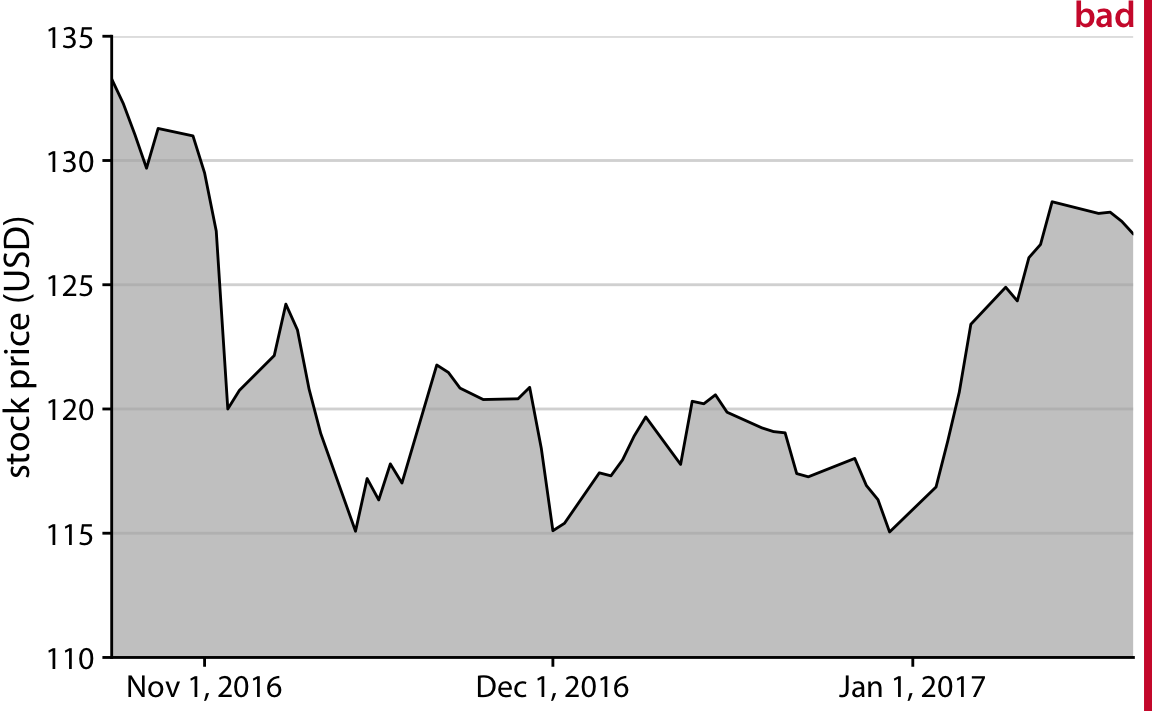
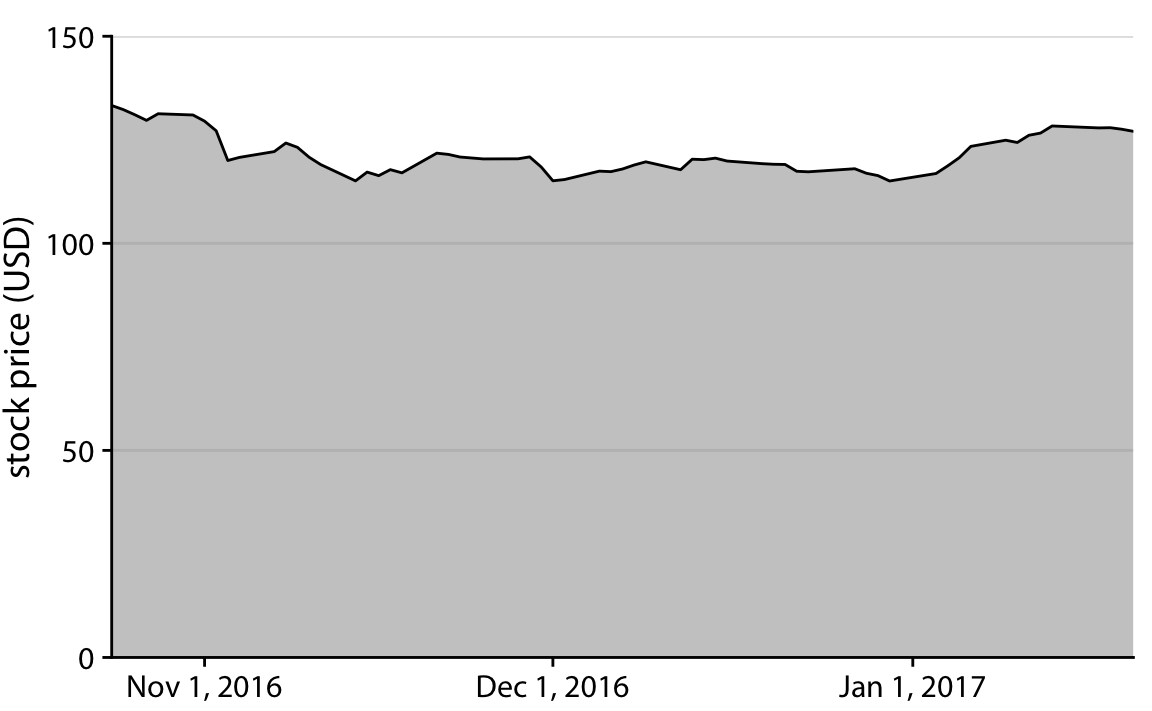
Alternative :
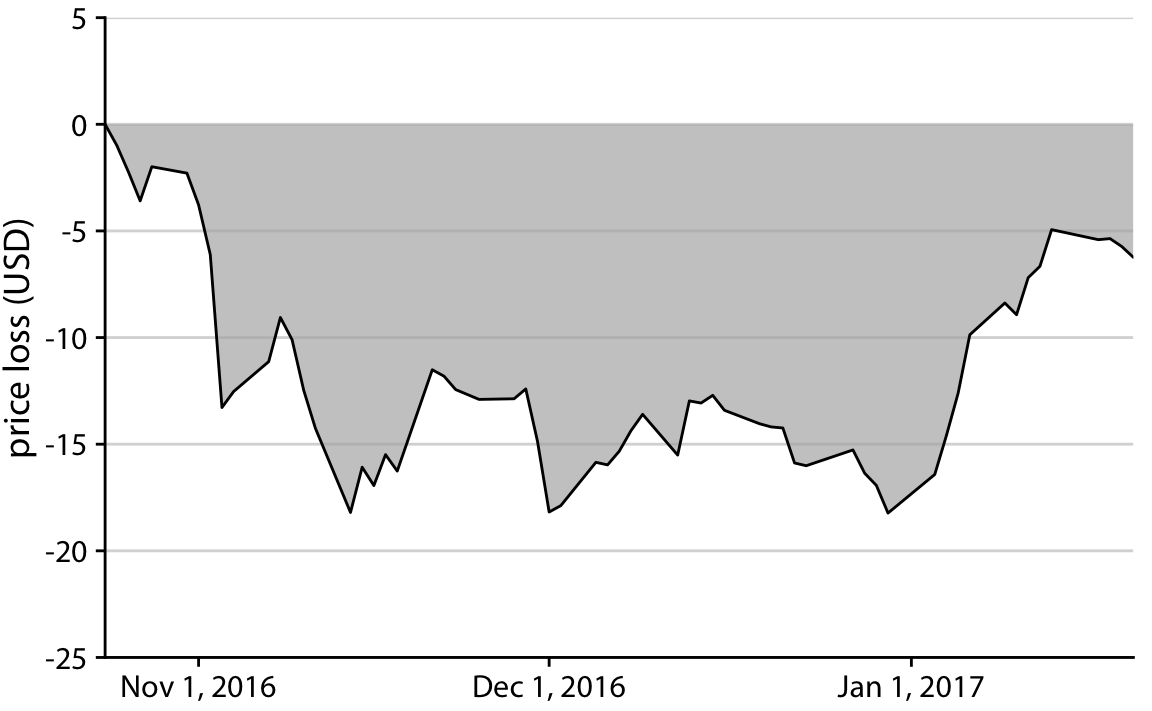
Le principe de la proportionnalité
- L’oeil humain est très sensible aux différences de longueur, mais moins aux différences de surface.
- Le diagramme en secteurs (camembert) comporte un double problème : ce sont les angles qui sont comparés, et non les surfaces, et il est d’autant plus difficile de comparer les angles entre eux.
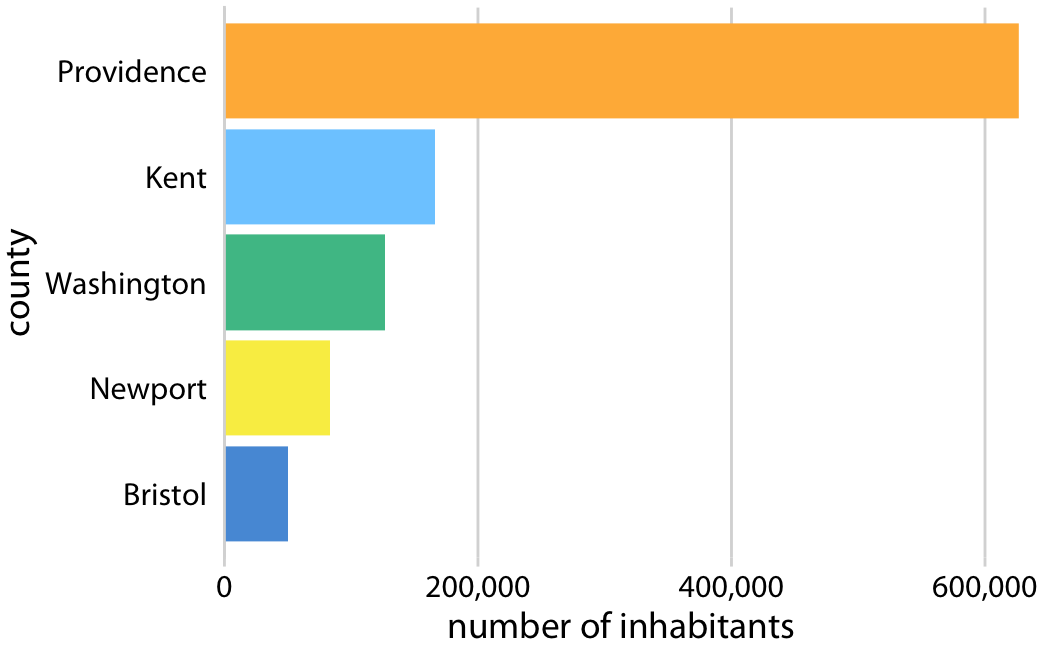
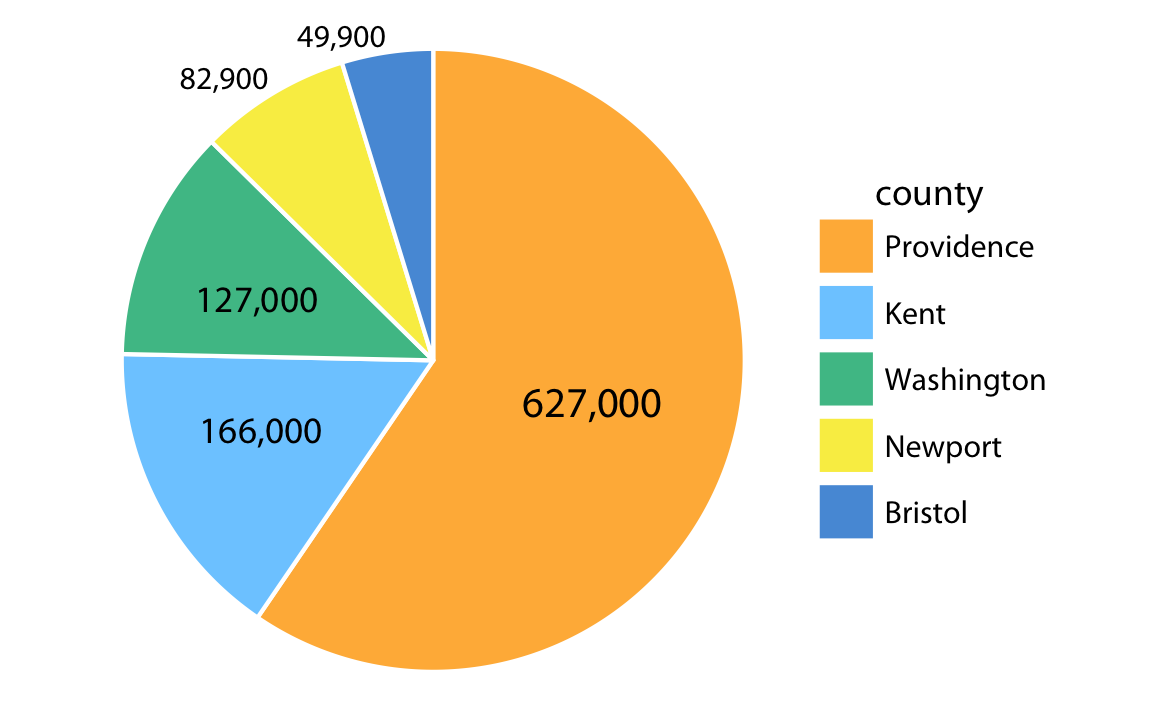
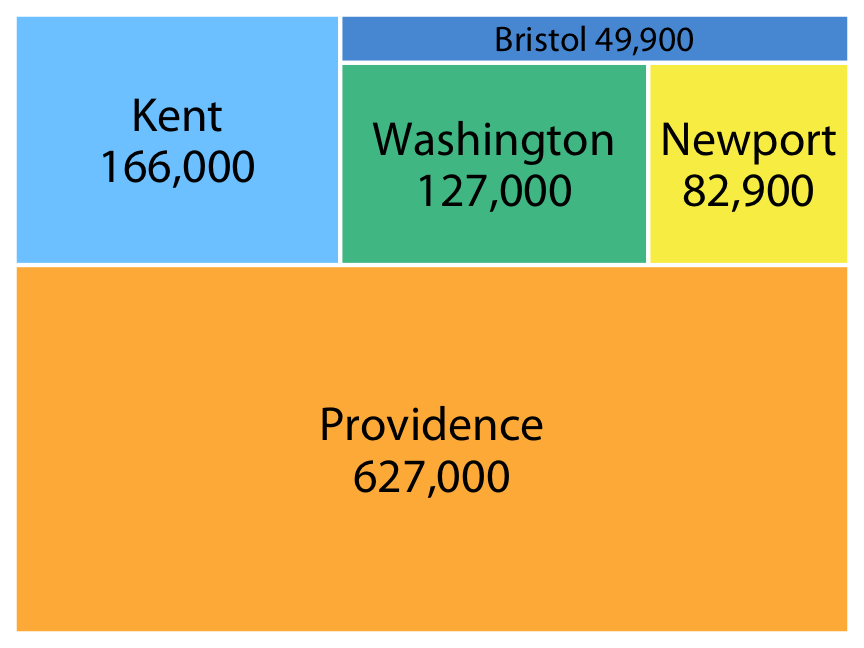
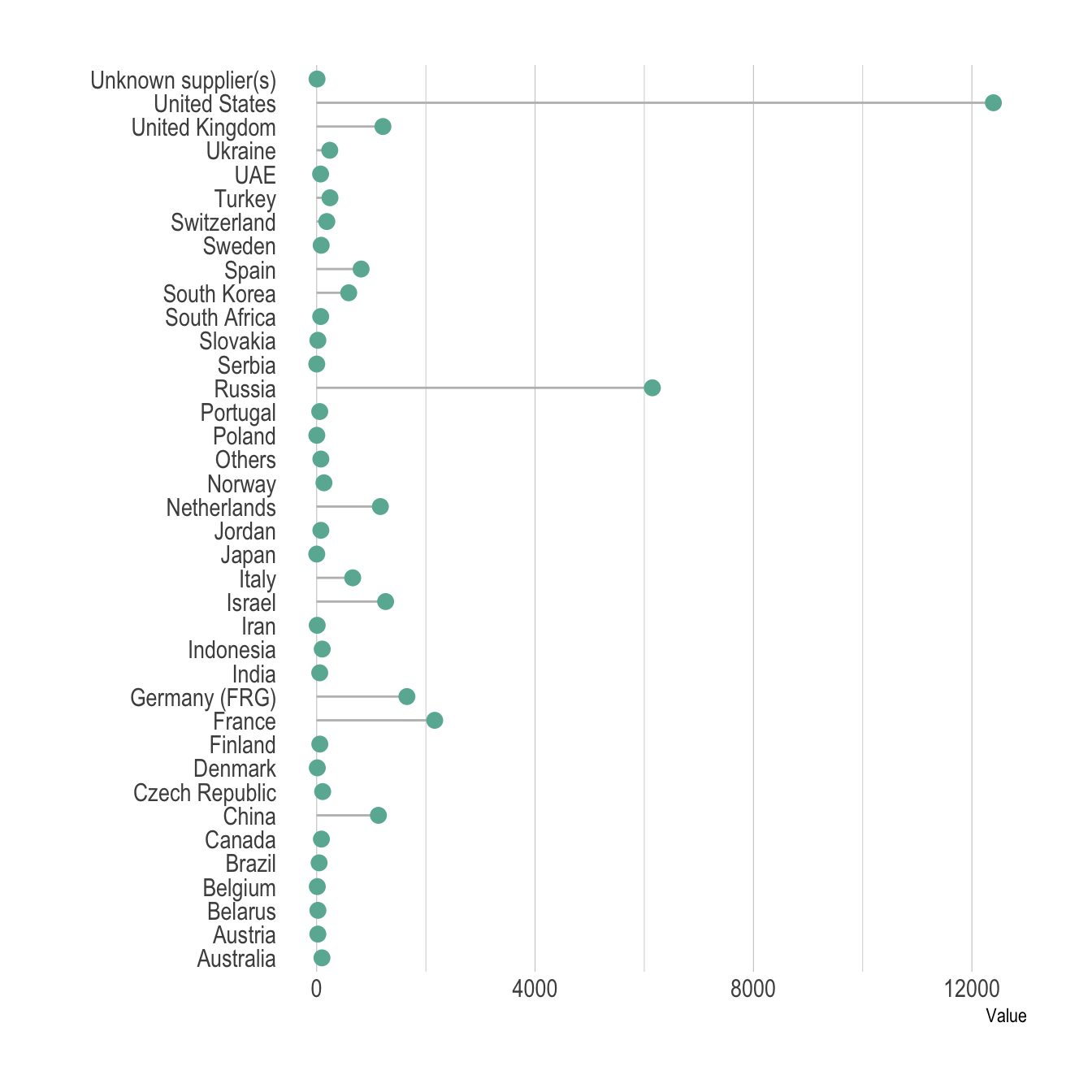
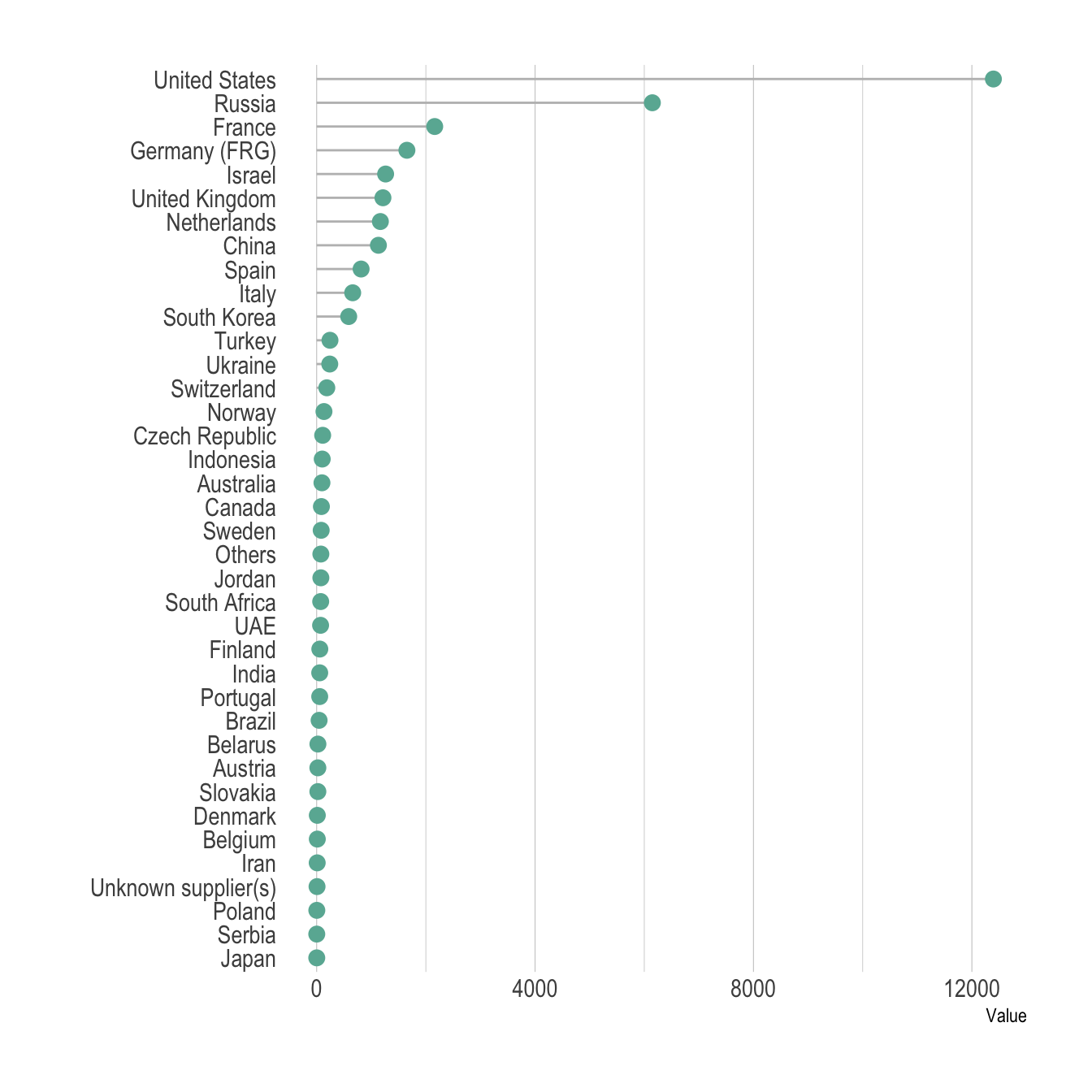
Tri des données
- Trier les données à afficher sur les axes pour faciliter la lecture.
Palettes de couleurs
- Attention aux personnes présentant des difficultés visuelles (daltonisme, etc.) : utilisez des palettes de couleurs adaptées.

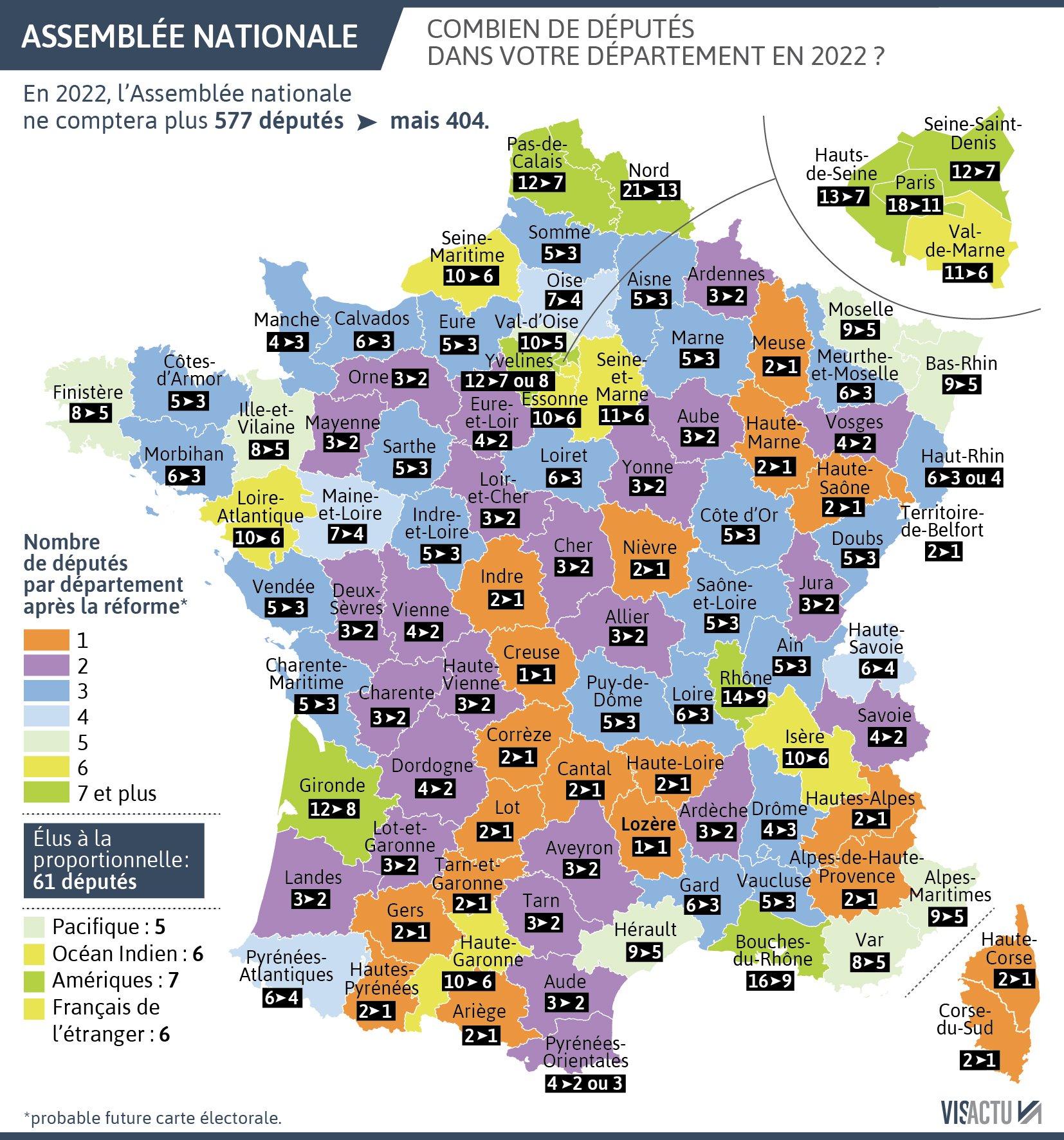
Palettes de couleurs
- Évitez les palettes de couleurs qui pourraient être confuses…
(+ évitez les différents autres problèmes de la carte de droite !)

Processus itératif
Prenez le temps nécessaire à configurer, modifier, tester, corriger, etc. votre visualisation de données : il s’agit d’un processus itératif.
Demandez des retours à vos collègues, à vos amis, etc.
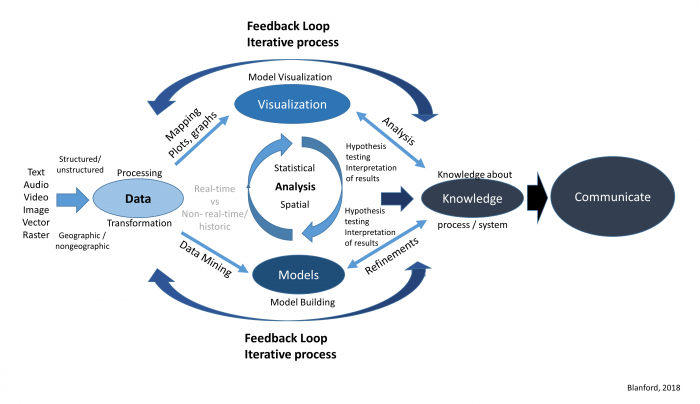
Source : https://www.e-education.psu.edu/geog586/node/808 - Credit: Blanford, © Penn State University, licensed under CC BY-NC-SA 4.0
Processus itératif
- Pensez à utiliser un gestionnaire de versions de code (Git, etc.) pour pouvoir revenir en arrière et travailler en équipe si nécessaire (sur la plateforme Observable il est possible de travailler à plusieurs sur un notebook et le code des notebooks est automatiquement versionné et il est ainsi possible de revenir à une version précédente).
Trouver des modèles inspirants
- Pour réaliser des visualisations de données efficaces, il est important de s’inspirer de modèles existants.

- Cf. les différentes ressources sur la page d’acceuil de ce cours.
… et éviter les erreurs classiques
Une partie des erreurs classiques sont résumées dans ce cours. D’autres peuvent être consultées sur la page suivante :
Une autre tentative de résumer des règles de base (et de quand il est OK de passer outre) est disponible sur la page suivante :
Si vous voulez vous faire peur, vous pouvez aussi consulter la page suivante dédiée aux visualisation de données ratées :
