{kind=link}
{kind=link}
{kind=link}
anscombe = [{"group":"I","x":10,"y":8.04},{"group":"I","x":8,"y":6.95},{"group":"I","x":13,"y":7.58},{"group":"I","x":9,"y":8.81},{"group":"I","x":11,"y":8.33},{"group":"I","x":14,"y":9.96},{"group":"I","x":6,"y":7.24},{"group":"I","x":4,"y":4.26},{"group":"I","x":12,"y":10.84},{"group":"I","x":7,"y":4.82},{"group":"I","x":5,"y":5.68},{"group":"II","x":10,"y":9.14},{"group":"II","x":8,"y":8.14},{"group":"II","x":13,"y":8.74},{"group":"II","x":9,"y":8.77},{"group":"II","x":11,"y":9.26},{"group":"II","x":14,"y":8.1},{"group":"II","x":6,"y":6.13},{"group":"II","x":4,"y":3.1},{"group":"II","x":12,"y":9.13},{"group":"II","x":7,"y":7.26},{"group":"II","x":5,"y":4.74},{"group":"III","x":10,"y":7.46},{"group":"III","x":8,"y":6.77},{"group":"III","x":13,"y":12.74},{"group":"III","x":9,"y":7.11},{"group":"III","x":11,"y":7.81},{"group":"III","x":14,"y":8.84},{"group":"III","x":6,"y":6.08},{"group":"III","x":4,"y":5.39},{"group":"III","x":12,"y":8.15},{"group":"III","x":7,"y":6.42},{"group":"III","x":5,"y":5.73},{"group":"IV","x":8,"y":6.58},{"group":"IV","x":8,"y":5.76},{"group":"IV","x":8,"y":7.71},{"group":"IV","x":8,"y":8.84},{"group":"IV","x":8,"y":8.47},{"group":"IV","x":8,"y":7.04},{"group":"IV","x":8,"y":5.25},{"group":"IV","x":19,"y":12.5},{"group":"IV","x":8,"y":5.56},{"group":"IV","x":8,"y":7.91},{"group":"IV","x":8,"y":6.89}]
Plot.plot({
grid: true,
inset: 10,
width: 928,
height: 240,
facet: {
data: anscombe,
x: "group"
},
marks: [
Plot.frame(),
Plot.dot(anscombe, {x: "x", y: "y"}),
Plot.linearRegressionY(anscombe, {x: "x", y: "y", stroke: "steelblue", ci: 0})
],
})Introduction à la visualisation de données
Cours 1 - 2025-2026
Matthieu Viry 
CNRS / UAR 2414 RIATE
September 8, 2025
Qu’est-ce que la visualisation de données ?
")
Les trois phases de la compréhension (Kirk, 2019, figure 1.4)
Pourquoi visualiser ?
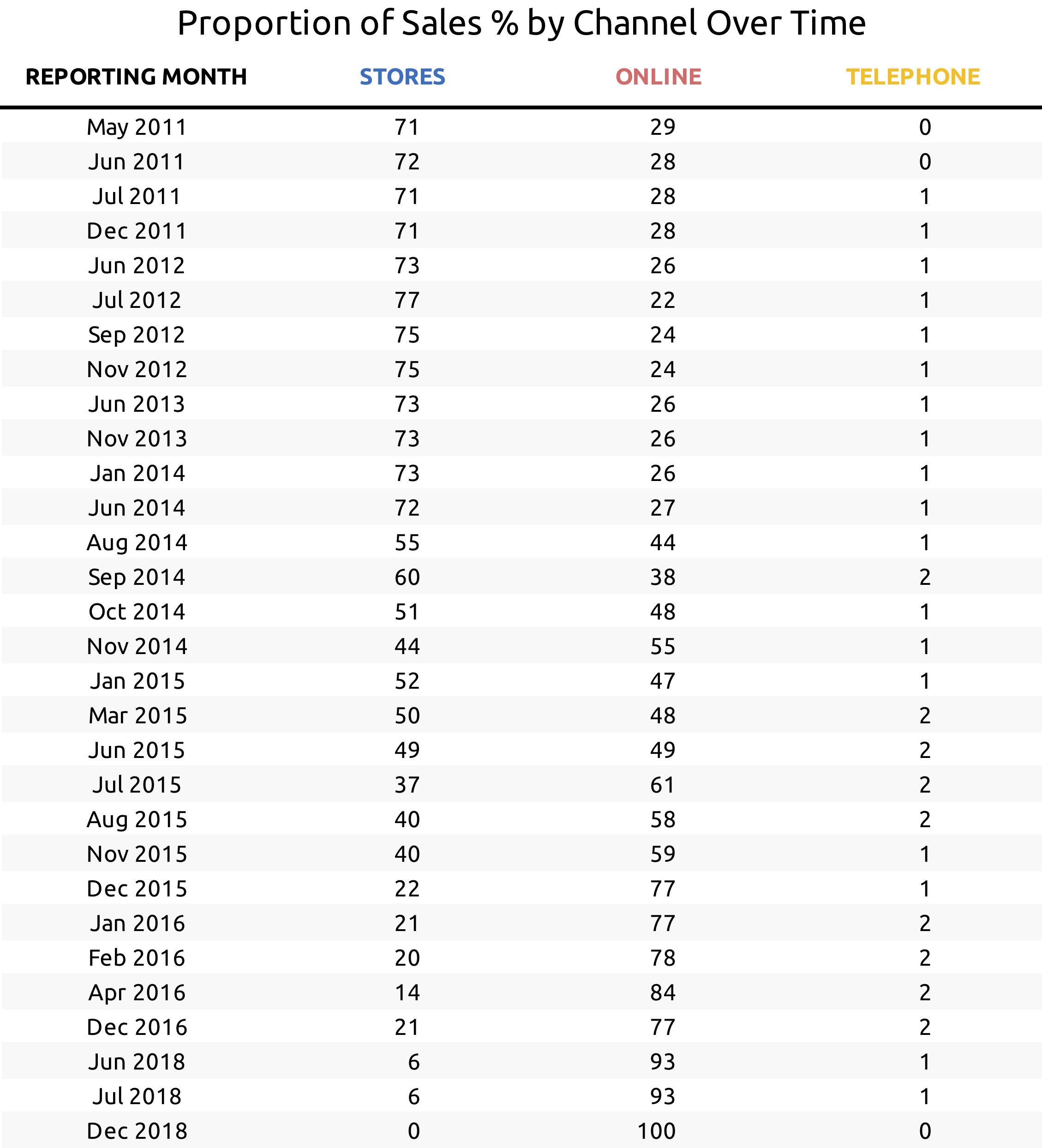
S’il est possible, à la lecture du tableau, de répondre à des questions simples comme “quel est le pourcentage de ventes réalisées online par le vendeur en Avril 2016 ?” (c’est 84),
…il est difficile de mener des réflexions plus générale comme “quelle est l’évolution de chaque canal de vente au cours du temps ?”.
Pourquoi visualiser ?
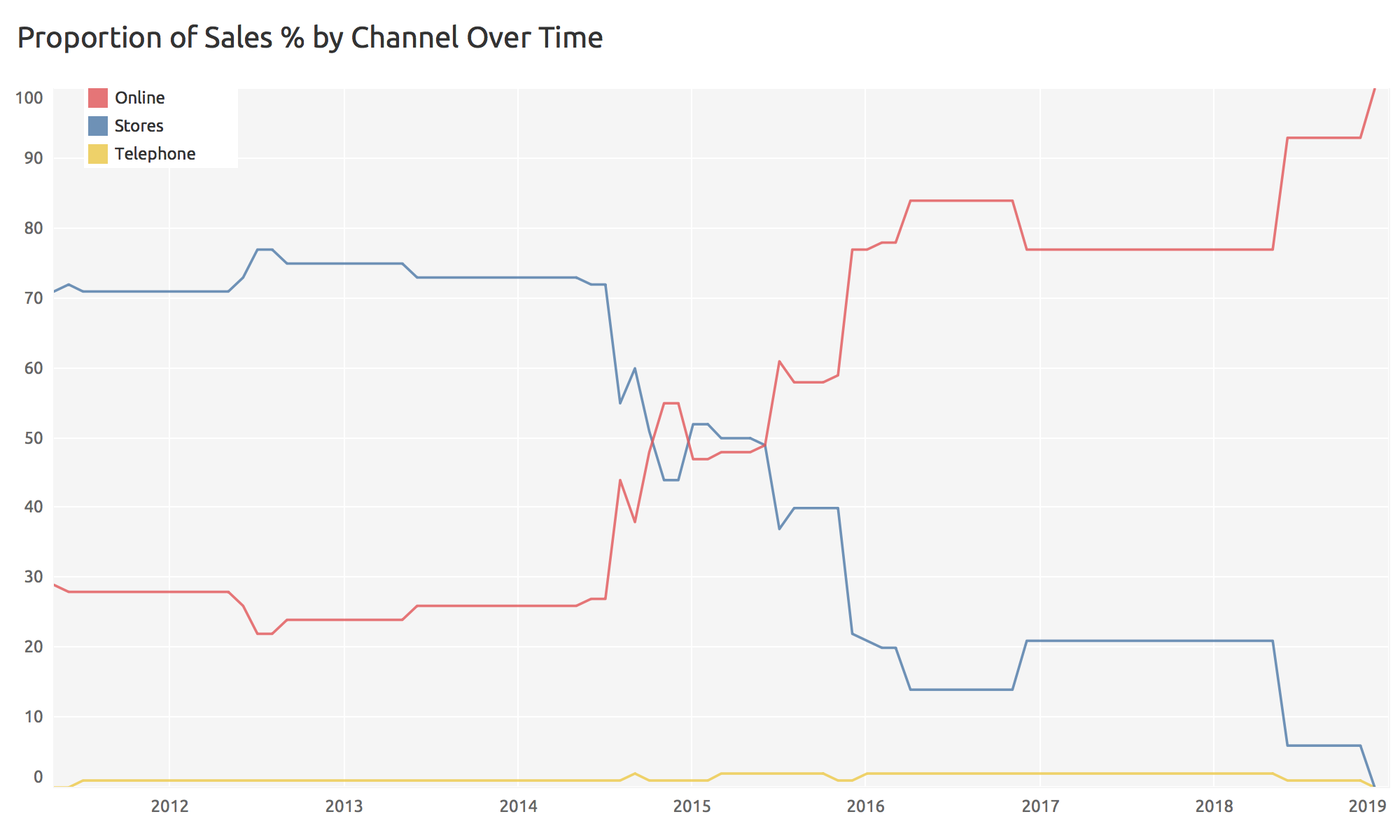
Proportion de ventes par type au cours du temps (Kirk, 2019, figure 1.3)
Pourquoi visualiser ?
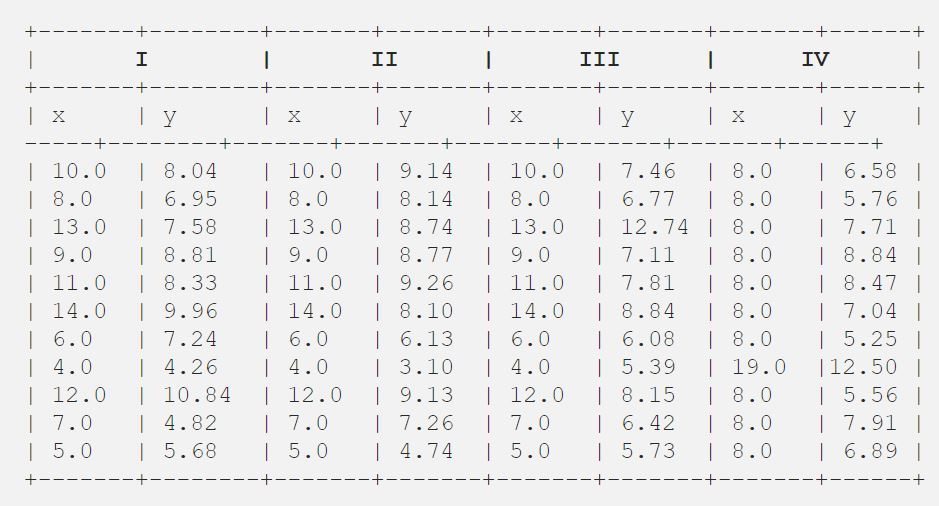
Dans un article de 1973, Francis Anscombe a publié quatre petits ensembles de données, aujourd’hui connus sous le nom de “quartet d’Anscombe”, afin de montrer les limites des statistiques sommaires.
Les quatre ensembles de données du quartet partagent plusieurs propriétés statistiques : leurs valeurs moyennes, leurs variances et leurs coefficients de corrélation.
| Mean X | Mean Y | Variance X | Variance Y | Correlation | |
|---|---|---|---|---|---|
| I | 9.0 | 7.5 | 11.0 | 4.125 | 0.816 |
| II | 9.0 | 7.5 | 11.0 | 4.125 | 0.816 |
| III | 9.0 | 7.5 | 11.0 | 4.125 | 0.816 |
| IV | 9.0 | 7.5 | 11.0 | 4.125 | 0.816 |
Sur le papier, ils semblent donc assez semblables les uns aux autres, mais lorsque nous les visualisons, ils sont clairement différents.
Pourquoi visualiser ?
Plus récemment, Alberto Cairo a conçu le DataSaurus pour faire le même constat : il faut visualiser les données pour voir le dino.

Des chercheurs d’AutoDesk ont mis au point un système astucieux pour créer des ensembles de données de formes différentes qui partagent des statistiques sommaires : https://www.research.autodesk.com/publications/same-stats-different-graphs/.
Histoire de la visualisation de données
Les prémices ?

Mouvement des planètes au cours du temps, par Macrobius, 10ème siècle (Source: https://commons.wikimedia.org/wiki/File:Mouvement_des_plan%C3%A8tes_au_cours_du_temps.png)
{kind=link}
Histoire de la visualisation de données
Les prémices ?
Des représentations graphiques en forme d’arbres ont été utilisées pour visualiser les relations familiales au moyen-âge (et probablement bien avant)

Arbre de Lulle, 15ème siècle (Source: https://fr.m.wikipedia.org/wiki/Fichier:ArborLulle.jpg)
{kind=link}
Histoire de la visualisation de données
Les prémices ?

Arbre généalogique de la famille Magia, 1578 (Source: https://gallica.bnf.fr/ark:/12148/btv1b8496581k/f28.item)
Histoire de la visualisation de données
Les pionniers - Nicolas Oresme (1322-1382)
- Méthode de représentation graphique des variations d’une grandeur (qu’il appelle qualité) en fonction d’une autre grandeur.
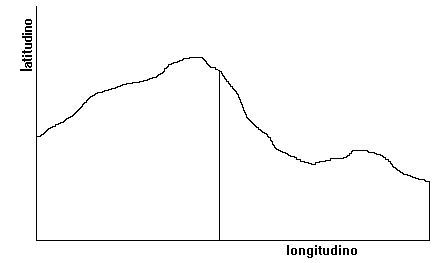
(Source: L’œuvre scientifique de Nicole Oresme, Alain Costé, 1997)
Histoire de la visualisation de données
Les pionniers - Charles-René de Fourcroy (1715-1791)
- Il est le premier à utiliser des diagrammes pour représenter des données statistiques.

Source : https://commons.wikimedia.org/wiki/File:Tableau_Pol%C3%A9ometrique,_1782.jpg
{kind=link}
Histoire de la visualisation de données
Les pionniers - Joseph Priestlet (1733-1804)
- Inventeur de la timeline moderne

Source : https://commons.wikimedia.org/wiki/File:A_New_Chart_of_History_color.jpg
{kind=link}
Histoire de la visualisation de données
Les pionniers - William Playfair (1759-1823)

Source : https://commons.wikimedia.org/wiki/File:Playfair_Barchart.gif
{kind=link}
Histoire de la visualisation de données
Les pionniers - William Playfair (1759-1823)
Source : https://commons.wikimedia.org/wiki/File:Playfair_piecharts.jpg
{kind=link}
Histoire de la visualisation de données
Les pionniers - William Playfair (1759-1823)
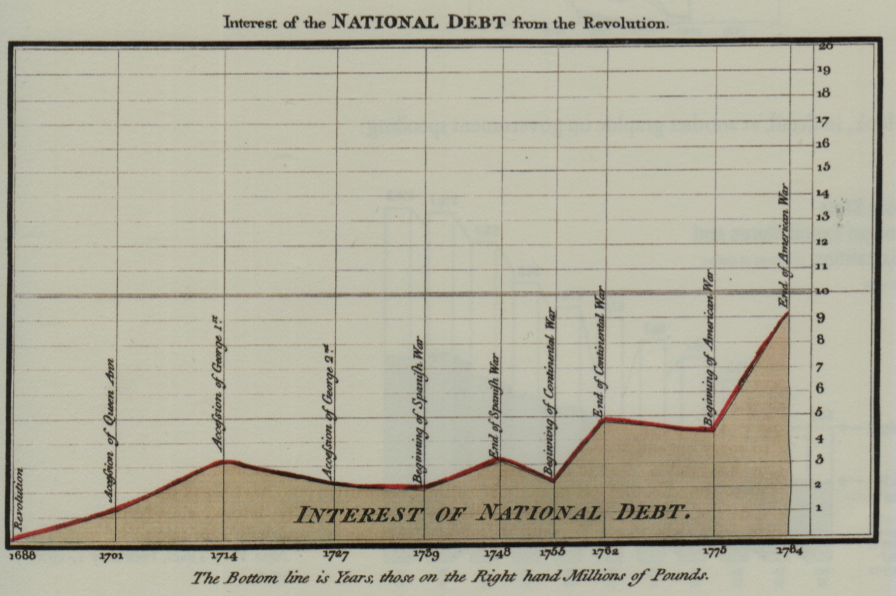
Source : https://commons.wikimedia.org/wiki/File:Playfair_interest_national_debt.png
{kind=link}
Histoire de la visualisation de données
Les pionniers - William Playfair (1759-1823)
Source : https://commons.wikimedia.org/wiki/File:Playfair_TimeSeries.png
{kind=link}
Histoire de la visualisation de données
Les pionniers - William Playfair (1759-1823)
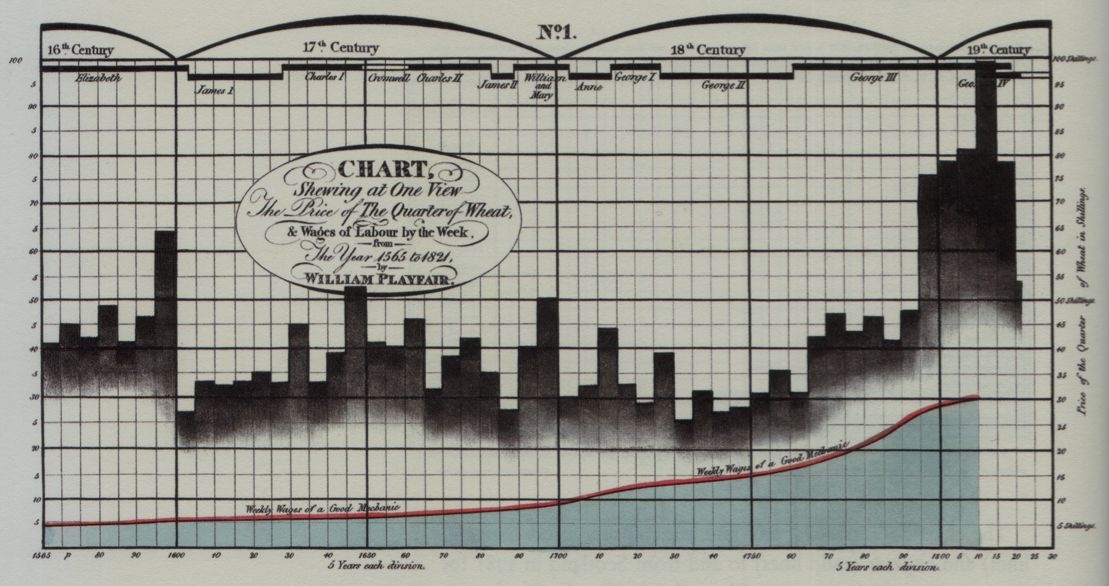
{kind=link}
Histoire de la visualisation de données
Les pionniers - Charles Joseph Minard (1781-1870)
- Pionnier de la visualisation de données géographiques et des représentations de type diagramme de flux.

Source : https://en.wikipedia.org/wiki/File:Minard.png
{kind=link}
Pour en savoir plus sur Minard : https://visionscarto.net/charles-joseph-minard-cinquante-cartes
Histoire de la visualisation de données
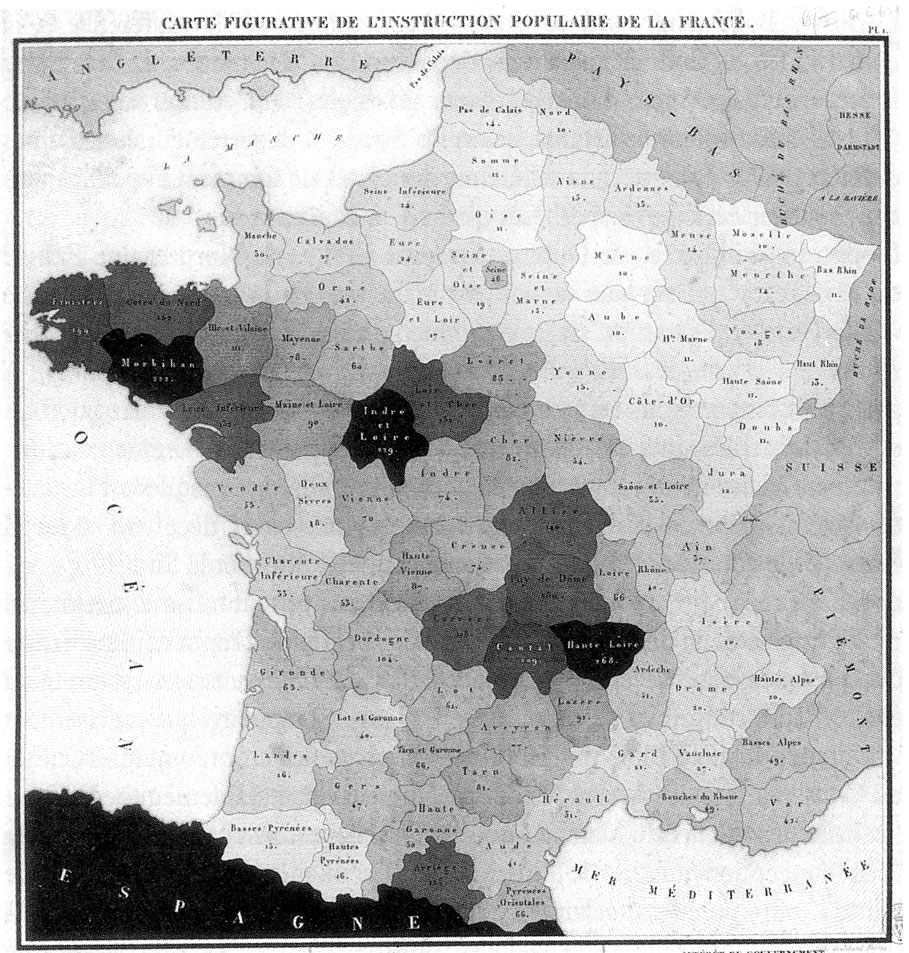
Les pionniers - Charles Dupin (1784-1873)
- Pionnier de la cartographie thématique (cartes statistiques / cartes choroplèthes)
{kind=link}
Histoire de la visualisation de données
Les pionniers - Florence Nightingale (1820-1910)
- Pionnière de la visualisation de données en santé publique et des représentations de type diagramme circulaire.
Source : https://commons.wikimedia.org/wiki/File:Nightingale-mortality.jpg
{kind=link}
Histoire de la visualisation de données
Au XXème siècle - Edward Tufte (1942-*)
- Publie l’ouvrage “The Visual Display of Quantitative Information” (1983), qui devient rapidement une référence dans le domaine de la visualisation de données
- décrit de nombreux principes de conception de visualisation de données
- présente de nombreux exemples de visualisation de données
- “lie factor”, “data-ink ratio”, “chartjunk”, etc.
- Popularise des représentation comme les mini-graphes (sparklines).

Source: https://fr.wikipedia.org/wiki/Visualisation_de_donn%C3%A9es
Histoire de la visualisation de données
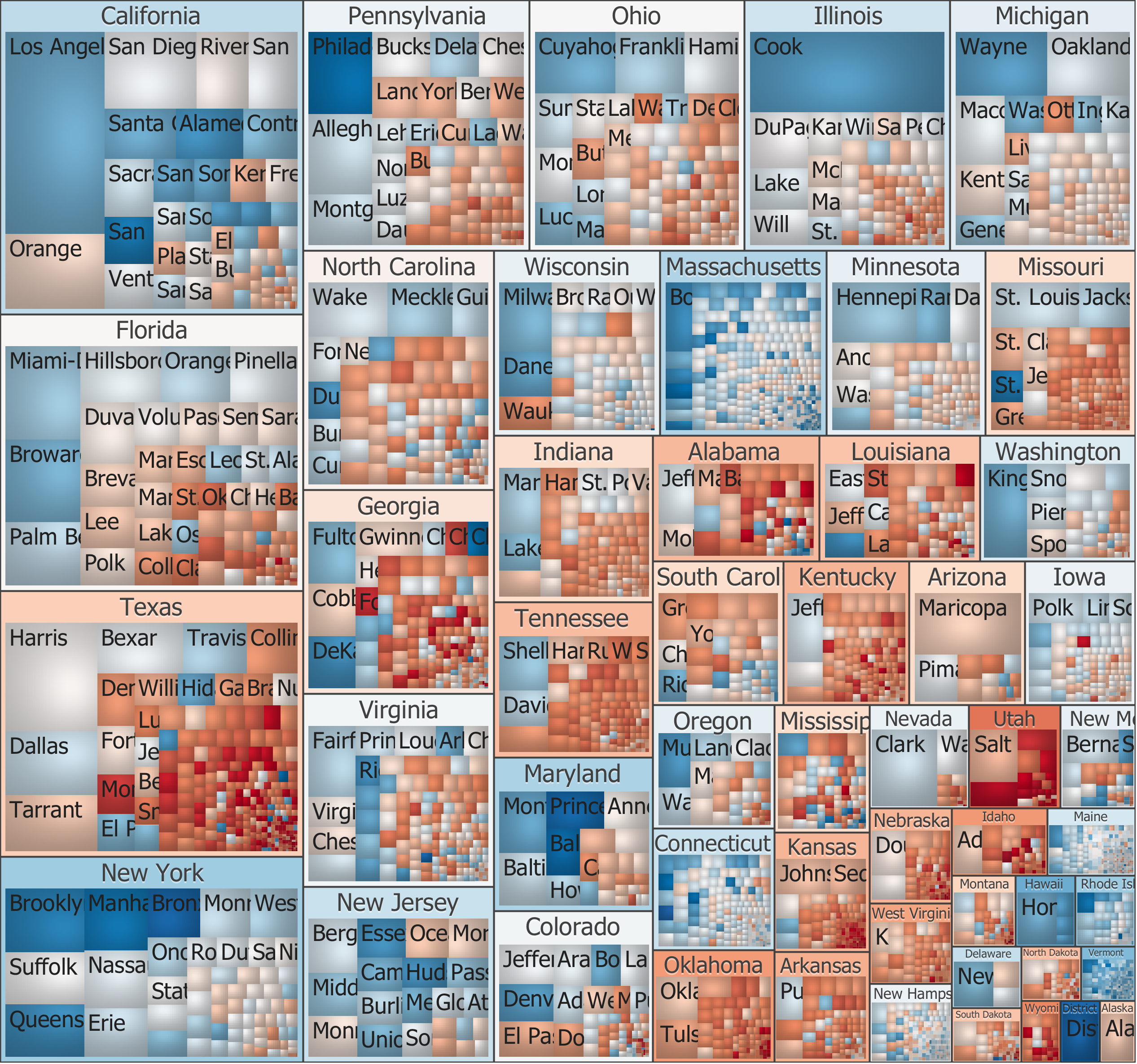
Au XXème siècle - Ben Shneiderman (1947-*)
Plutôt dans ce qu’on pourrait qualifier d’information visualisation que de data visualisation à proprement parler
Propose le modèle de visualisation overview first, zoom and filter, then details on demand (1996)
Propose les treemap (1992)
Les principaux types de visualisation (1)
Visualiser des quantités
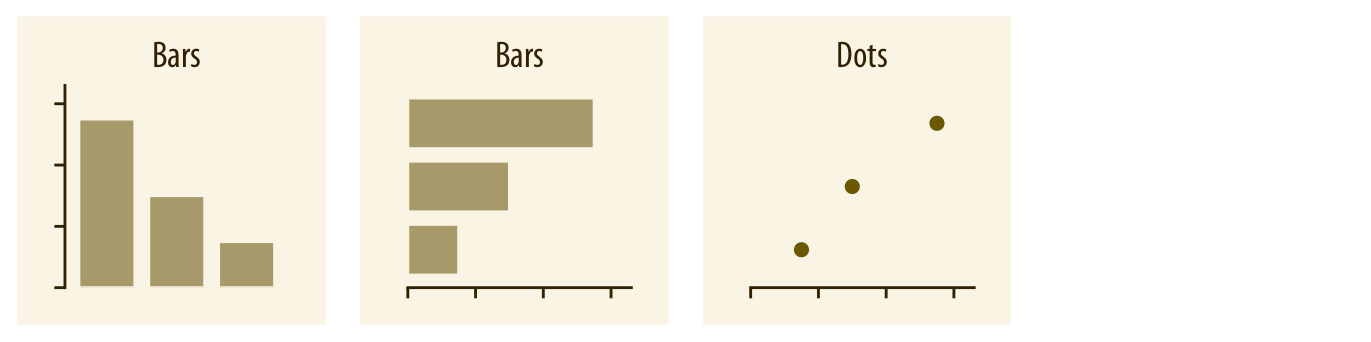
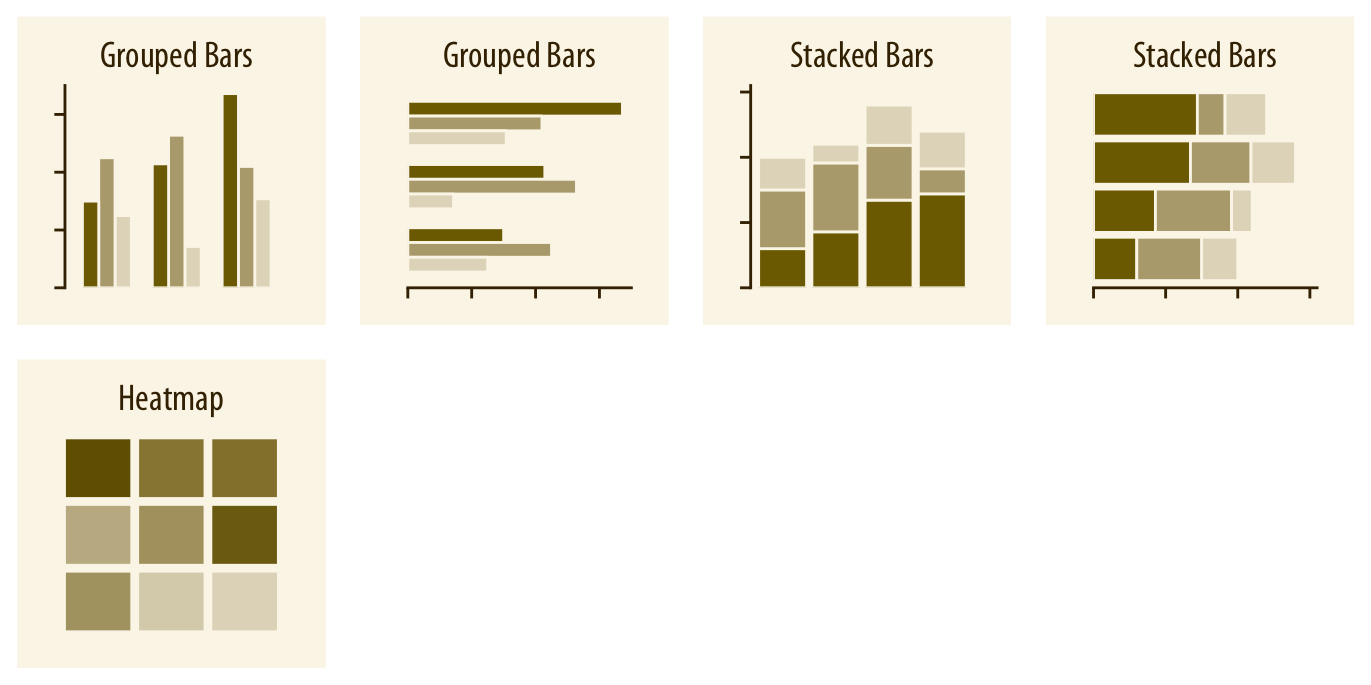
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Diagramme à barres
- Digramme à barres groupées
- Diagramme à barres empilées
- Carte de chaleur
Les principaux types de visualisation (2)
Visualiser des distributions
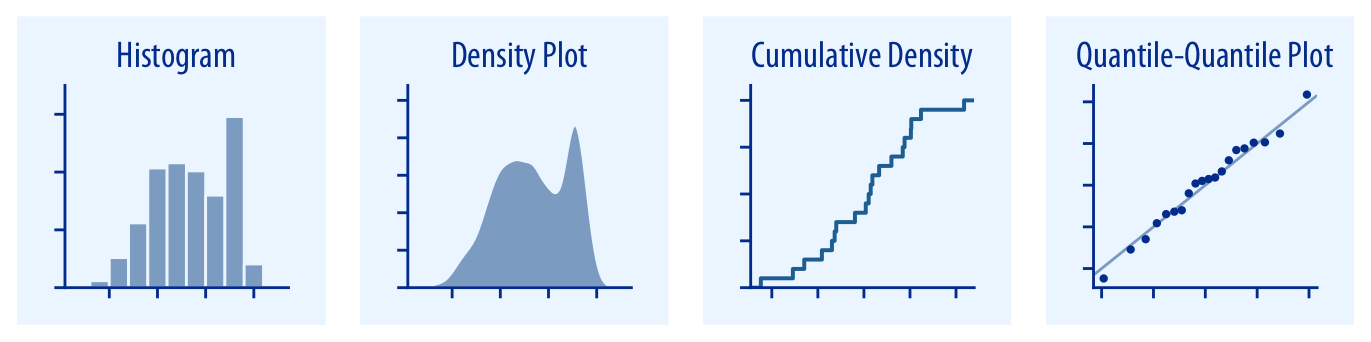
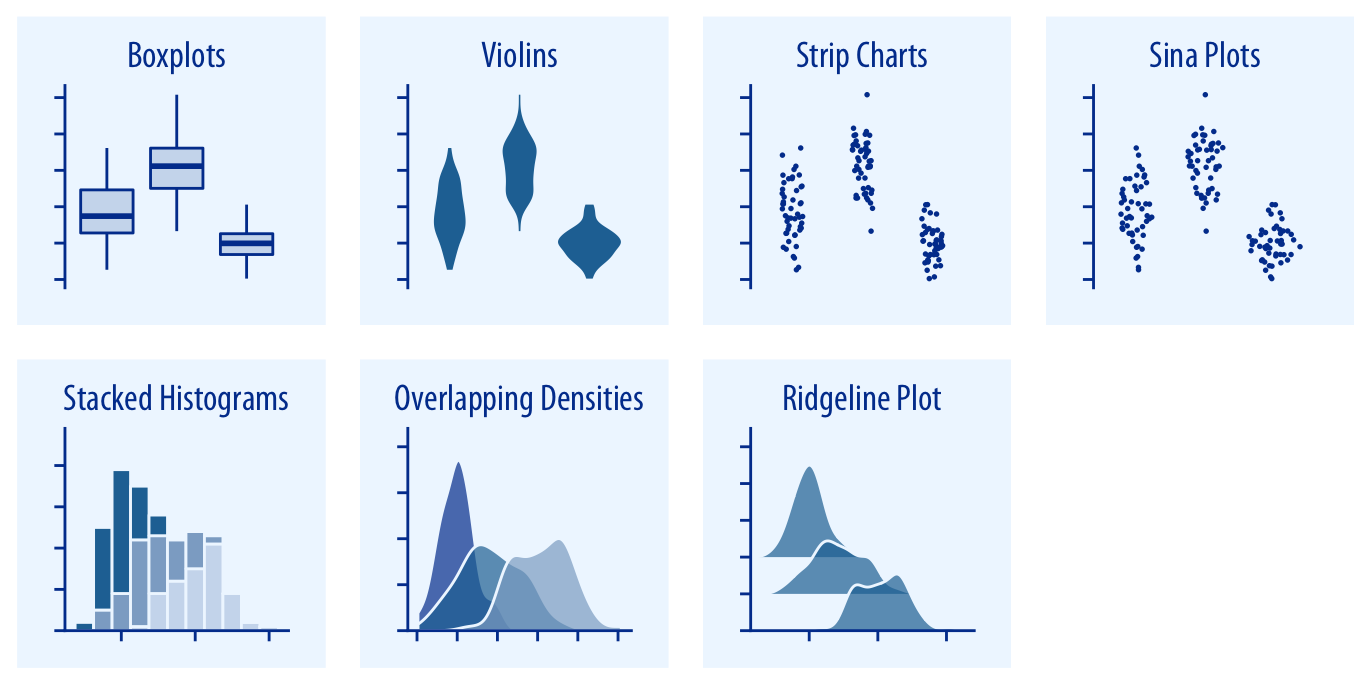
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Histogramme, Diagramme de densité,
Diagramme de densité cumulée,
Diagramme quantile-quantile - Boîte à moustaches, Diagramme en violon, etc.
- Histogramme empilé,
Diagramme de densité empilé, etc.
Les principaux types de visualisation (3)
Visualiser des proportions
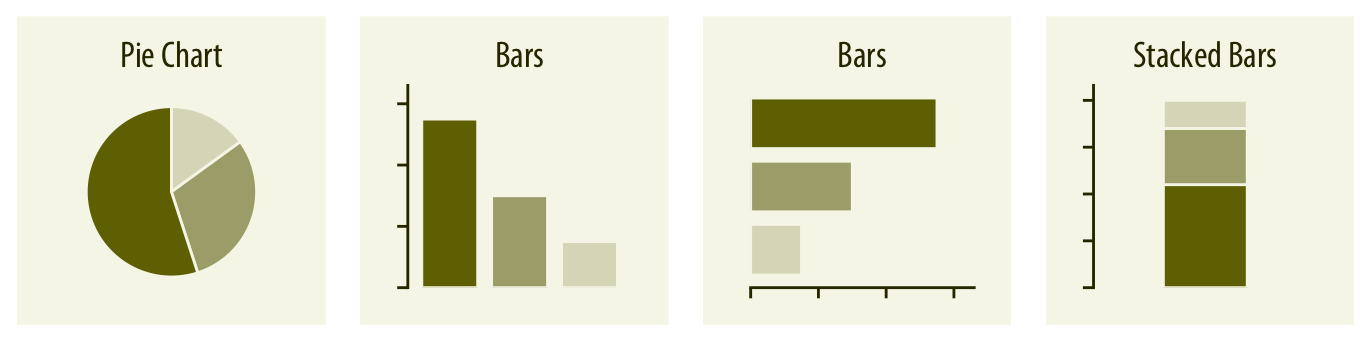
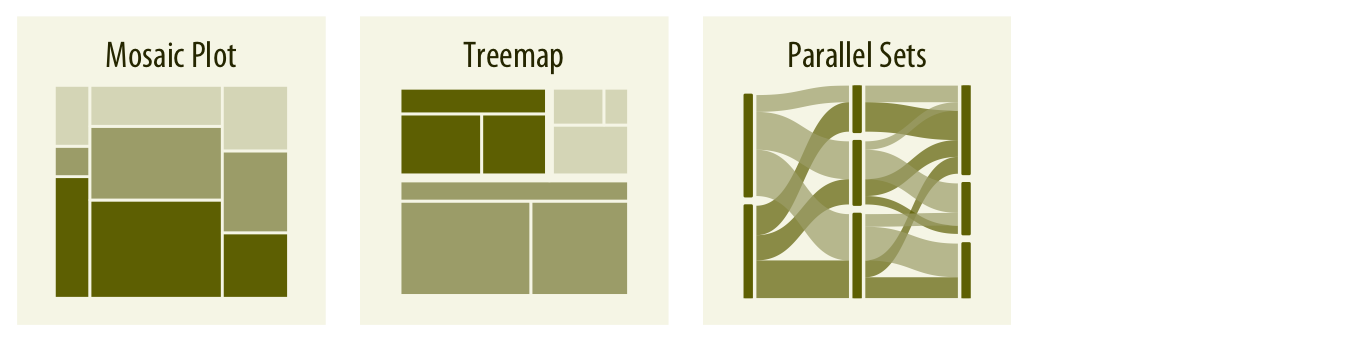
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Diagramme circulaire (ou à secteurs), diagramme à barre et diagramme à barre empilée
- Carte proportionnelle ou carte à cases (treemap)
- Parallel sets / Diagramme de Sankey / Diagramme alluviaux
Les principaux types de visualisation (4)
Visualiser des proportions et les comparer
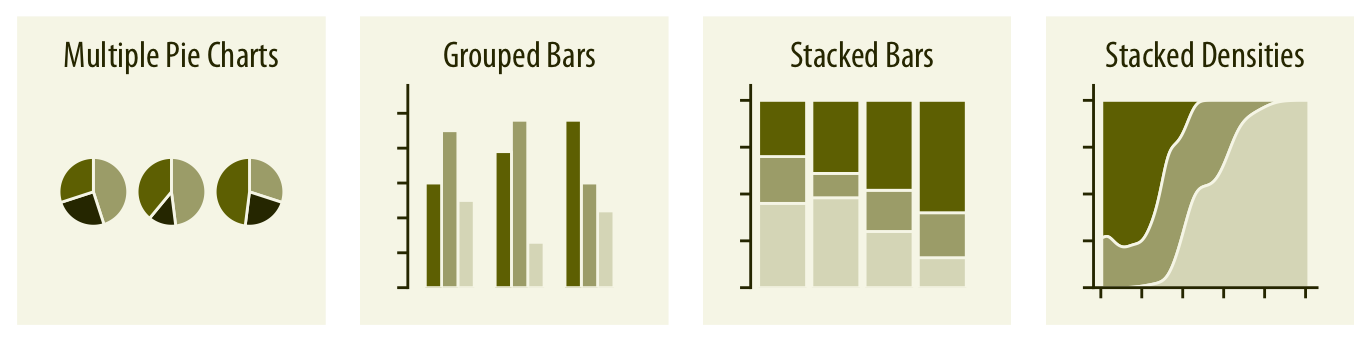
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Notion de facettage (faceting, small multiples)
Les principaux types de visualisation (5)
Relations x-y / entre deux variables
Des représentations simples…
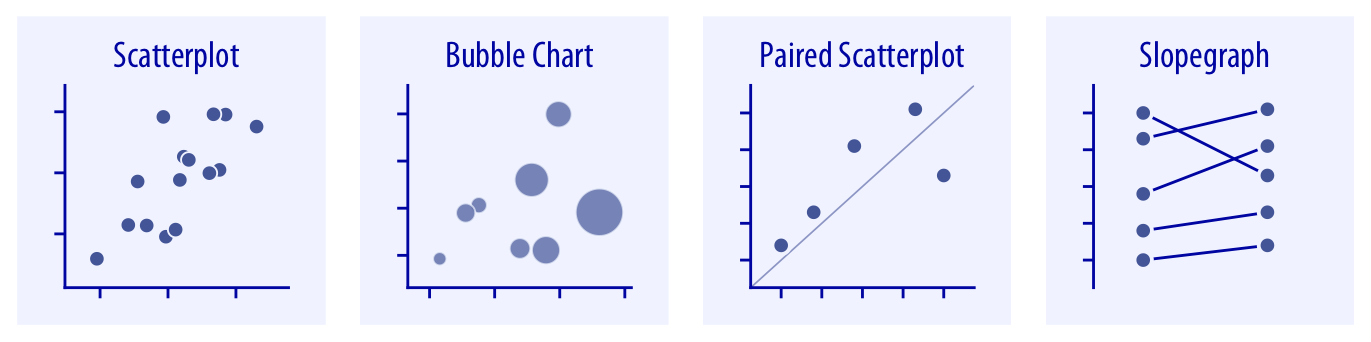
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Nuage de points, graphique à bulles
Les principaux types de visualisation (6)
Relations x-y / entre deux variables
Ou plus complexes…
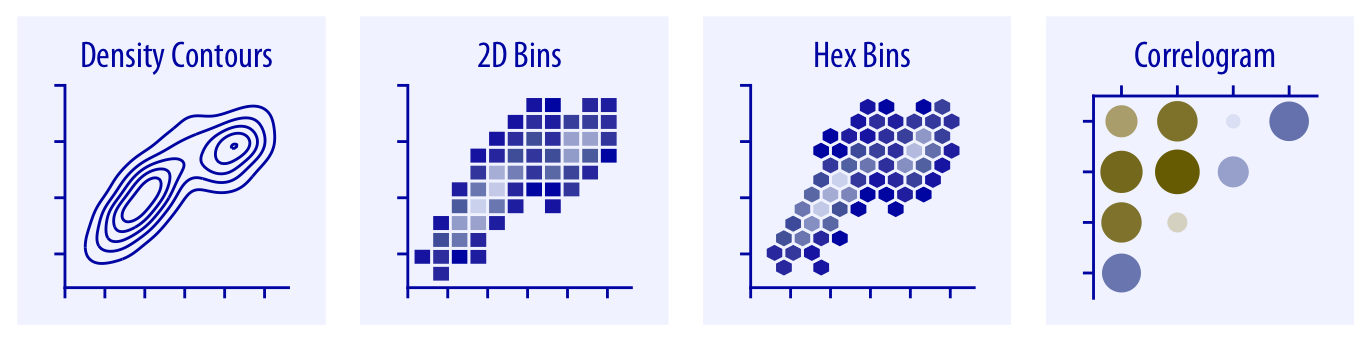
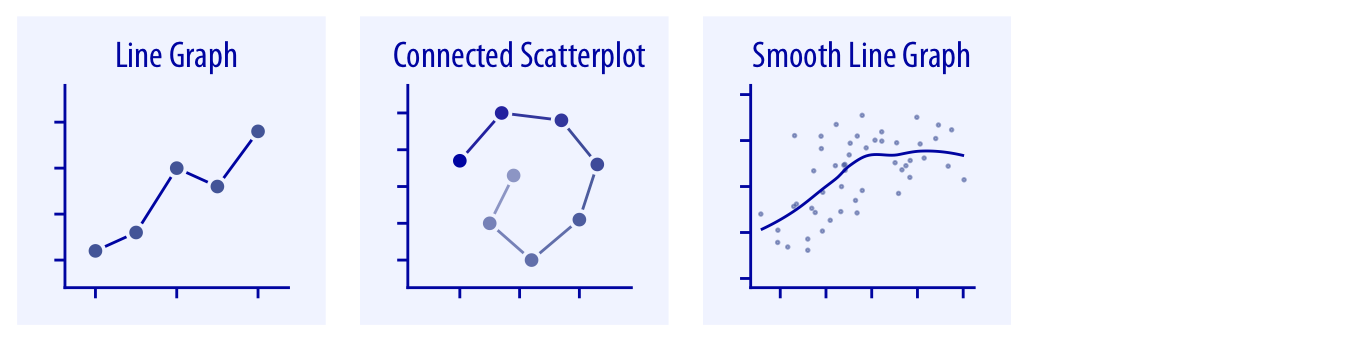
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Contour de densité de points, regroupement en cellule ou regroupement hexagonal, corrélogramme
- Diagramme à ligne brisée (diagramme linéaire), diagramme linéaire lissé
Les principaux types de visualisation (7)
Visualiser des données spatiales
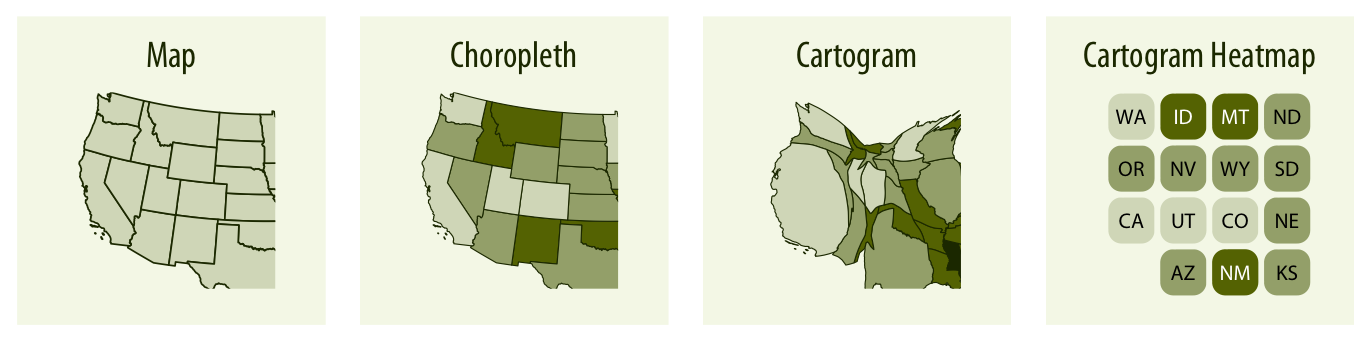
Source: Fundamentals of Data Visualization,
Claus O. Wilke, 2019 (Licence CC BY-NC-ND 4.0)
- Carte de localisation
- Carte choroplèthe
- Carte de symboles proportionnels
- Cartogramme (carte à aire égale / anamorphose)
Les outils de visualisation (2)
Bibliothèques de visualisation
En JavaScript :

Les outils de visualisation (3)
Bibliothèques de visualisation
En R :
- Ggplot2
- Plotly
- rbokeh
- Highcharter
- Etc.

Les outils de visualisation (4)
Bibliothèques de visualisation
En Python :
- Matplotlib
- Seaborn
- Plotly
- Bokeh
- Altair
- Etc.
Exemple avec Chart.js
- Une bibliothèque qui propose des types de graphiques :
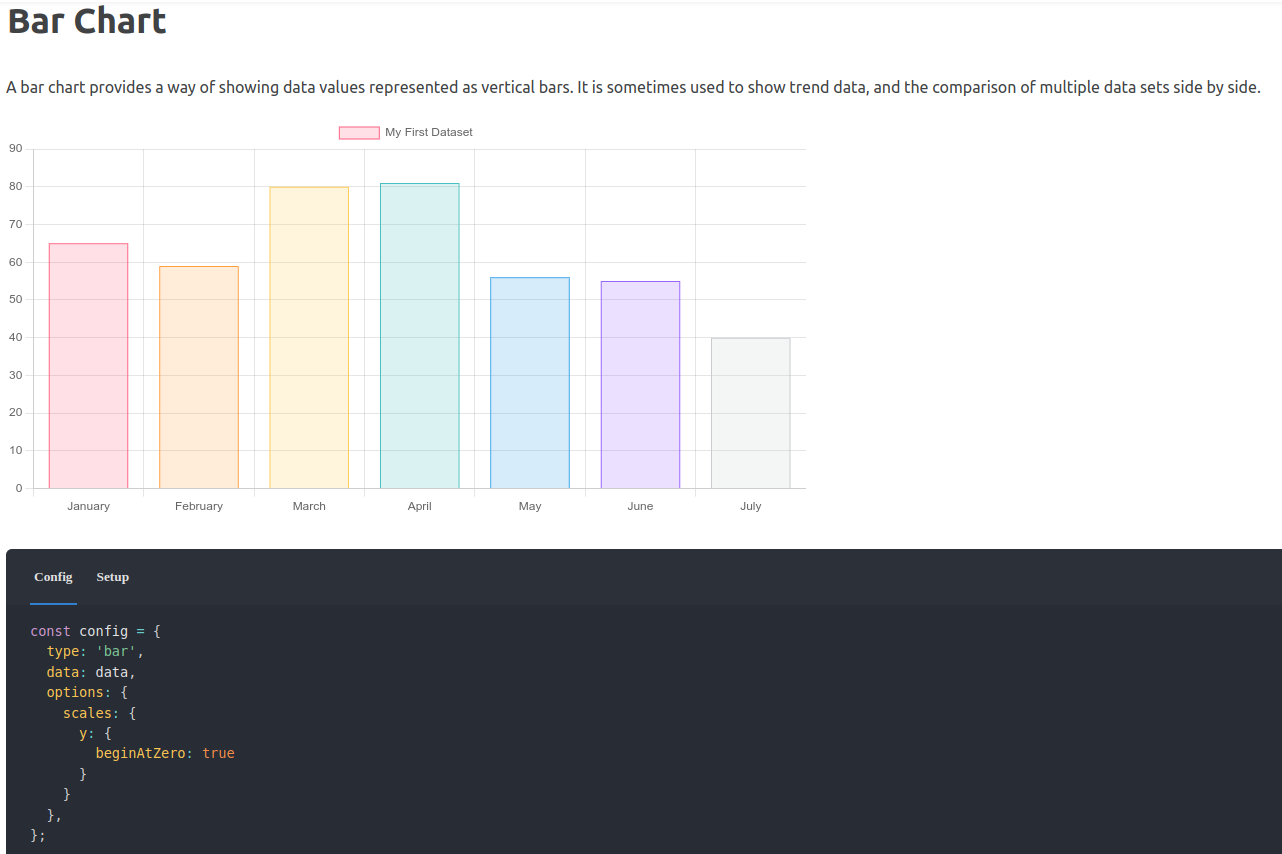
Dans le cadre de ce cours…
Observable Plot
Observable Plot est une bibliothèque open source de visualisation développée notamment par Mike Bostock (le créateur de D3.js) et Philippe Rivière (un des principaux contributeurs de D3.js).
Elle permet de créer rapidement des visualisations en utilisant la grammaire des graphiques, en utilisant la puissance de D3.js mais sans nécessiter d’être un développeur JavaScript confirmé.
![]()
Dans le cadre de ce cours…
D3.js
Data-Driven Documents (lier sélectivement les données d’entrée à des éléments de HTML, en appliquant des transformations dynamiques pour générer et modifier le contenu)
Il s’agit d’une puissante bibliothèque open source de visualisation de données développée également Mike Bostock (et d’autres contributeurs).
Plutôt low-level (permettant un contrôle très fin des visualisations créées, aux dépens de la complexité du code)
![]()